
この記事は、 Techouse Advent Calendar 2024 22日目の記事です。
昨日は Niranabe さんによる 「ドキュメントでなくコードで語れ ~RuboCopのカスタムルールで規約を記述する~」でした。
まえがき
はじめまして、 codingalone です。 Techouse ではクラウドハウス労務チームで開発を担当しています。
Techouse では AWS をフル活用してサービスを提供していますが、利用しているサービスの1つに Amazon Neptune があります。 Amazon Neptune 、ご存知でしょうか? Amazon Neptune は高速かつ、高い可用性とスケーラビリティをもつフルマネージドのグラフデータベースサービスです。
といっても、そもそもグラフデータベースがどのようなものかご存知でない方も多いのではないでしょうか。
本記事では、実際に弊社の SaaS プロダクト「クラウドハウス労務」に Amazon Neptune を導入した事例を紹介し、 RDB との対比で Amazon Neptune (グラフデータベース) がどういったものかをご紹介したいと思います。
以下、長いので Amazon Neptune は必要に応じて Neptune と表記していきます。
Amazon Neptune とは
まず、 Neptune を例にグラフデータベースがどういったものかを簡単にご説明します。
みなさんも普段から使われているであろうリレーショナルデータベース (RDB) では、データは表の形で保存されるイメージですよね。
グラフDBにおいてデータは、エンティティを指す ノード とノード間の関連を表す エッジ として、 ネットワーク状 に保存されます。
(後述する Neptune のクエリ言語ではそれぞれ Vertex, Edge と呼びますが、伝わりやすいので本記事ではノード、エッジで説明します)
また、ノードとエッジには ラベル と呼ばれる名称と、 プロパティ と呼ばれる値を持たせることができます。
次の図は、従業員 (employee) と部署 (department) の関係を RDB 風・グラフDB風で表現したものです。
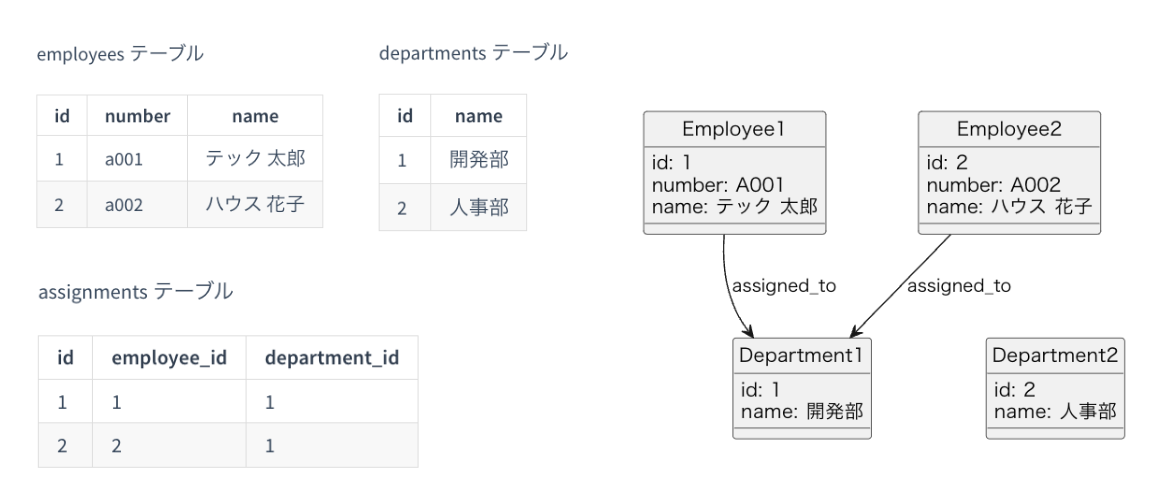
左側は RDB 風です。 employees 、 departments テーブルにそれぞれレコードがあり、また従業員が部署に所属することを表すための中間テーブル assignments があります。
右側がグラフDB風ですが、こちらでは Employee1 、 Employee2 と Department1 が assigned_to というラベルのついたエッジで紐づけられていますね。
モデリングで記述したクラス図の検証としてオブジェクト図 (クラスのインスタンス間の関連を示した図) を書いたりすると思いますが、
オブジェクト図がそのままデータとして保存されているようなイメージを持つと良いかと思います。
グラフデータベースはノードとその間にあるエッジを次々に辿ってデータを探索するのが得意だとされており、 たとえばクレジットカードの利用履歴や傾向から不正使用を検出する目的や、 レコメンデーションエンジンのバックエンドDBなどとして活用されるケースがあるようです。
なぜ Amazon Neptune を選んだのか
クラウドハウス労務での Amazon Neptune の使い方
前述のように、深い関連を辿るデータ探索が得意であるというグラフDBの特性から、例えば木構造のデータ探索において強みが発揮できると言えそうです。
クラウドハウス労務が取り扱っている人事労務のドメインにおいて、木構造のデータというとまず組織構造が浮かびます。
企業によっては組織エンティティ、つまり部署の数は数百から数千にのぼる場合もあり、親部署 → 子部署 → 孫部署 ... という組織階層は何層にも至ります。
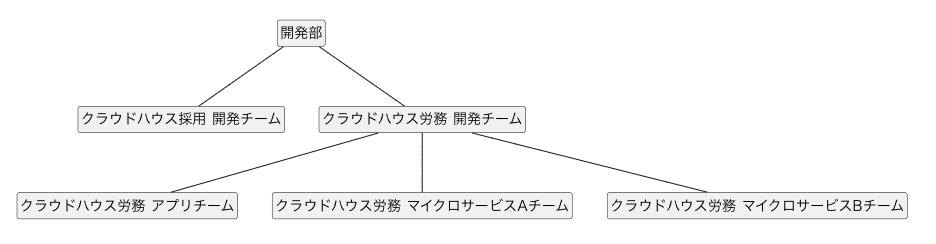
例えば次のようなモデル、テーブルですね。 RDB を使って正規化すると、再帰的な関連で表現できます。

木構造で表すとこのような形になります。
クラウドハウス労務では、管理者が操作することができるデータや機能を制御するための、権限データベースとして Neptune を活用しています。
権限制御の一例として、「ある管理者は、特定の複数部署の配下の全部署を閲覧することができる」というユースケースがあります。
上の木構造でいえば、特定の部署の下のツリーをすべて辿るという走査になります。
権限はあらゆる操作で常にチェックされるものなので、高速なアクセスが求められます。
実装イメージ
「特定の部署の配下の全部署を閲覧することができる」ことを確認するための、対象となる部署一覧を取得するクエリを RDB (ここでは PostgreSQL) と Neptune で比べてみます。
まずはみなさんにもなじみのある SQL で実装した場合がどうなるか書いてみます。 SQL では再帰的なテーブル探索では WITH RECURSIVE が使えますね。
前述の departments テーブルの例で、「クラウドハウス採用・労務の開発チームとその配下のすべての部署の ID を取得する」というクエリだとこうなります。
WITH RECURSIVE department_tree AS ( SELECT id, parent_id, name FROM departments WHERE id in (2, 3) -- クラウドハウス採用 開発チーム, クラウドハウス労務 開発チームの部署ID UNION ALL SELECT d.id, d.parent_id, d.name FROM departments d INNER JOIN department_tree dt ON d.parent_id = dt.id ) SELECT id FROM department_tree;
これと同等のデータを取得するクエリを、 Neptune でデータ操作をするクエリ言語である Gremlin で書くとおよそこんな感じになります。
g.V().has(id, within(2, 3)) .repeat( __.aggregate('x') .out('parent_to') .aggregate('x') ).until( __.outE('parent_to') .count().is(0) ).cap('x').unfold();
... おやっ、これはなんでしょうか? Groovy ですね。
はい、 Gremlin は Groovy をインターフェースとして実装されており、このようなメソッドチェーンでクエリを書いていきます。
さて、それではいずれもクエリプロファイルを取って比較してみましょう。
なお ID はここではダミーに差し替えていますが、いずれのクエリも同じ組織構造・本番相当のデータ量・サーバースペックにおいて、65レコードの結果を返すクエリとして実行したものです。
もちろん完全に同等の条件にはできませんが、極端にどちらかの実行環境が高速であったり低スペックであったりはしない状況での計測だと思っていただければと思います。
まずは Amazon Neptune から。
Neptune では https://${your-neptune-endpoint:port}/gremlin/profile にクエリを投げるとプロファイルレポートが得られます。
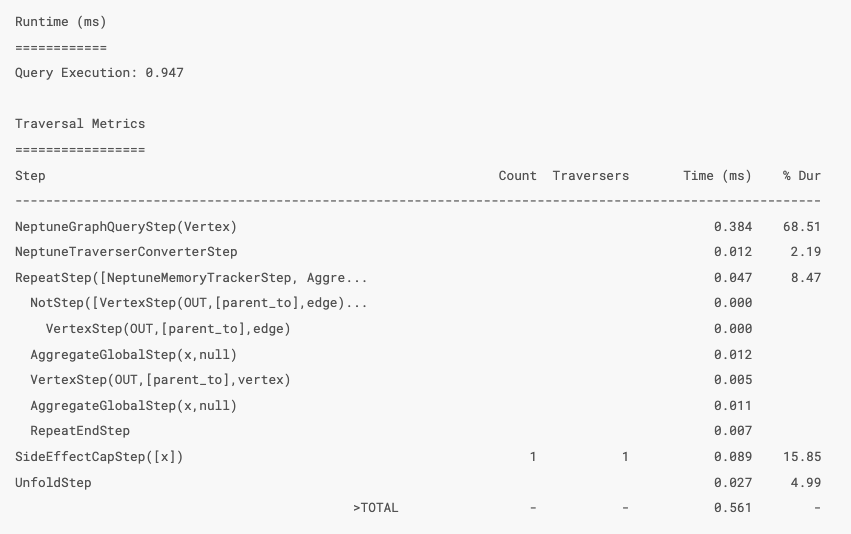 (上記はクエリプロファイルから一部を抜粋したものです)
(上記はクエリプロファイルから一部を抜粋したものです)
全然わからないと思うのですが、これは要は PostgreSQL で EXPLAIN ANALYZE を実行した結果だと思っていただければよいです。
Traversal Metrics というのはクエリ実行にかかった時間がわかるレポートで、 Time でどこにどの程度時間がかかっているかを見てクエリチューニングに役立てられます。
Query Execution: 0.947 というのが実際にクエリ実行にかかったトータルの時間です。
Traversal Metrics と乖離が結構あるのはデシリアライズの時間がかかったりしたためと思われます。 1ms を切っていますね。速い。
では SQL の方も PostgreSQL で EXPLAIN ANALYZE をしてみます。
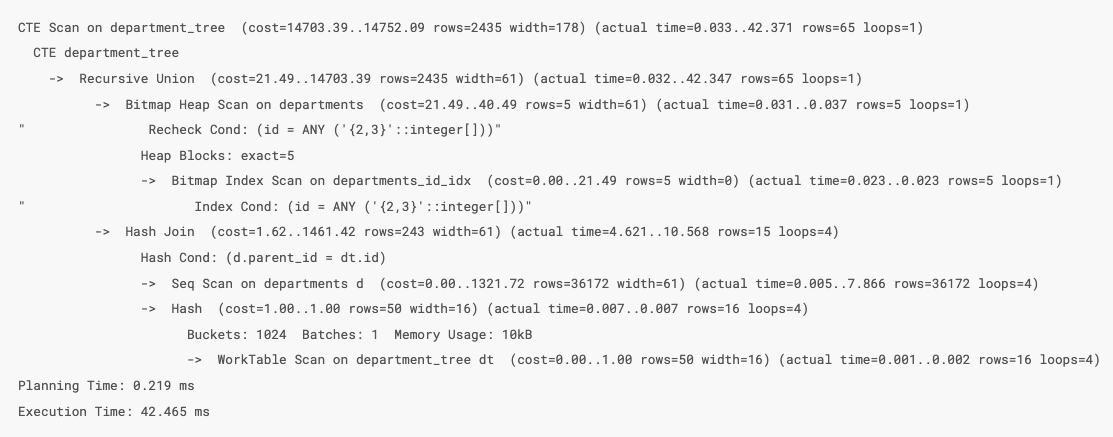
テーブルを再帰検索しているのでコストが大きそうですね。
Neptune 0.947 ms vs. PostgreSQL 42.465 ms という結果となりました。再帰的な構造におけるデータ走査において Neptune はかなり速いと言えそうです。
異なる性質のデータベースなので単純比較はできないということは念頭におきつつも、今回の目的であるデータを取得するうえで Neptune は有利だということがおわかりいただけたかと思います。
Amazon Neptune を使ってきて感じた強みと弱み
クラウドハウス労務で Amazon Neptune を使い始めてまもなく3年ほどになります。
クラウドハウス労務ではメインの DB として Aurora PostgreSQL を利用しているので、 PostgreSQL との対比で考えて見たいと思います。
先に述べたような「深い関連を高速に走査することができる」という点以外にも、グラフ DB には次の様な強みがあると考えています。
直感的なデータモデリングができる
記事冒頭、グラフ DB と RDB の比較で用いた図を再掲します。
上の図で表した RDB ・グラフ DB のデータはいずれも、次のクラス図を元にしたものです。
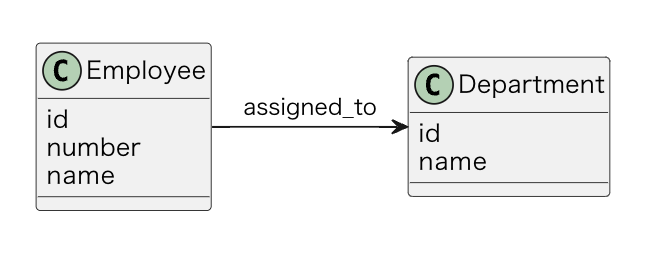
このクラス図に、 Assignment というクラスがあるわけではないことにご注目ください。
そうです。中間テーブル assignments というのはデータモデル上にしか存在しない概念なのです。
グラフ DB のデータを示した右側のダイアグラムであれば、 Employee と Department のインスタンスであるノード同士が assigned_to というエッジで繋がれている、とてもわかりやすいデータ構造となります。
クラス図から展開したオブジェクト図がそのままデータ構造になるという点は、概念モデリングとデータモデリングがシームレスになりとても良い体験でした。これは個人的にはかなり興味深い特徴だと思っています。
とはいえ、データモデリングにおける課題がまったくないというわけではありません。
直感的なデータモデリングが可能な一方で、 RDB では普遍的に使われている正規化などのプラクティスがグラフ DB には適用できないということでもあります。
現在のクラウドハウス労務のような、大規模データを前提としたエンタープライズシステムのデータ構造を設計するとなると、非正規化を含めたデータモデルを検討する必要も出てくることと思います。
RDB であれば社内・社外含めて知見を持っている人が多いのですが、グラフDBについての情報は少ないため、手探りで検討していくことになりそうです。
スキーマレスなので柔軟なデータ登録が可能
Neptune は RDB のテーブルのようにデータ型の定義を持たないので、非常に柔軟にデータを取り扱うことができます。
新しい種類のノードやエッジを追加するのにスキーマ定義を変更する必要がありません。新たなノードを追加するクエリを実行するだけです。
RDB であればデータ構造の定義を変更するのにマイグレーションを実行したり、データ移行をしなければならなかったり、そもそも既存データへの影響を考えるとデータ型の変更ができないといった場合もありますね。
一方、これは裏を返せば DB の制約によってデータの整合性を保つことはできないという見方もできます。
RDB では厳密なスキーマ定義や外部キー制約などによって、データベース単体でデータの整合性を保つことができます。
業務システムのように強いデータ整合が求められる場面においては、 RDB を選択するのはとても合理的なのだと言えます。
(Neo4j など、スキーマやデータへの制約が定義できるグラフ DB もあります)
Ruby on Rails との統合で考えると...
クラウドハウス労務は Rails を使って実装していますが、 RDB であれば ActiveRecord が使えるという利点はとても大きいです。
Neptune はまだまだ新しいサービスですので、対応する ORM が実はほとんどなかったりします。
ちなみに弊社では Grumlin という Gem を採用していますが、このライブラリはクエリジェネレータなので、それ以外の機能は自前で実装しています。
ふだんの開発ではバリデーションからクエリ結果のオブジェクトへのマッピング、アソシエーションの取得など ActiveRecord に様々な面で助けられていますので、 Rails を使う上で ActiveRecord の恩恵はとても大きいなと感じます。
というわけで Rails との統合においては RDB に軍配が上がります。
まとめ
グラフ DB と Amazon Neptune 、そしてその実用例をご紹介し、 RDB との対比の中で Neptune の強み・弱みについて述べてきましたが、いかがでしたでしょうか?
どちらにも長所・短所がそれぞれあり、正直なところユースケースに応じて使い分けるべきとしか言いようがないものではあります。
ですがあえて言うならば、現在私たちが開発しているクラウドハウス労務のような業務系のシステムにおいては、 RDB を使った方が享受できるメリットが比較的多いのではないかと考えています。
やはりスキーマ定義や制約によってデータベース単体でデータ整合・トランザクション整合を保てる RDB は魅力的です。
また、 RDB ・ SQL は 広く使われている枯れた技術であり、利用者も多く安定しています。 Neptune のクエリ言語である Gremlin はなかなかクセが強く、社内でも浸透しづらくスケールの観点で難がありました。
木構造データを高速に走査したいという要件についても、 RDB を使った上でパフォーマンスを改善するというアプローチもあるかと思います。
Neptune を選択したことが失敗だったとは思っていませんが、チャレンジングな取り組みだったとは感じています。
面白いことばかりでなく大変な部分もありましたが、それに臆することなく技術的な挑戦は続けていきたいものです。
こういった新しい技術やチャレンジングな取り組みに関心がある方は、ぜひ他のブログ記事や、イベント等での弊社の情報発信を見ていただけたら嬉しく思います!
Techouseでは、社会課題の解決に一緒に取り組むエンジニアを募集しております。 ご応募お待ちしております。