
はじめに
こんにちは、株式会社 Techouse のクラウドハウス採用でエンジニアインターンをしている ReLU と申します。
いきなりですが、以下のグラフをご覧ください。
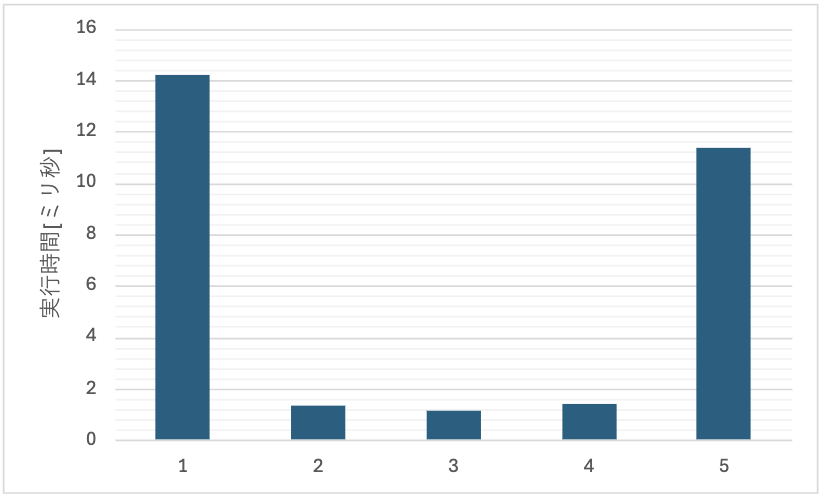
これは PostgreSQL の実行計画を取得した結果です。
あえてグラフタイトルや横軸の説明は隠しているのですが、実行時間の差が非常に大きいことがわかると思います。
実行計画とは、データベースが SQL クエリを実行する際に、どのようにデータを操作するかを決定するための詳細な手順のことです。クエリを実行して期待される結果を得る方法にはいくつかの選択肢があり、その選択によって処理の効率が大きく異なります。PostgreSQL は、これらの選択肢の中から最も効率的だと判断した方法を実行計画として作成し、それに基づいてクエリを実行します。この選択は、これまでに収集された統計情報(テーブルのサイズやデータ分布)、インデックスの有無などをもとに計算されます。
「パフォーマンスが悪いクエリと良いクエリを叩いただけでしょ。」
と思われるかもしれませんが、実はこの結果はある何かを変えて同じテーブルに対して同じクエリを叩いた時のグラフです。
今回は、私の DB の理解が甘くて非常にパフォーマンスが悪いテーブルを作成しそうになったことについて紹介させていただきます。
やりたかったこと
私が所属しているクラウドハウス採用というサービスは、採用管理における人事業務を電子化して採用担当者を支援するサービスです。また、採用管理に加えて、自社ブランドに合わせたデザイン・構成の採用サイトを作成することが出来ます。これに合わせて、クラウドハウス採用では企業が持つサイトのことをウェブサイト、人事担当者をオペレータと呼んでいます。また、ウェブサイトが開催する説明会などを管理するために管理画面上から説明会を作成でき、ここではセミナーと呼ぶことにします。
現在のウェブサイト、オペレータ、セミナーの関係としては以下の図のようになっています。
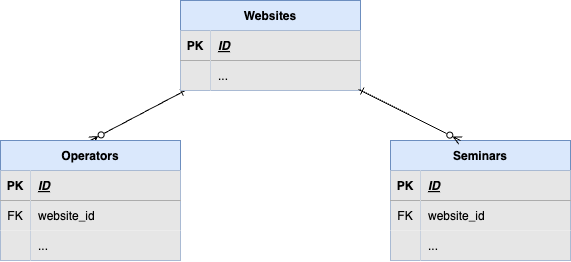
今回開発する機能で、セミナーの担当者を設定したかったのでオペレータとセミナーの間に中間テーブルが必要になりました。
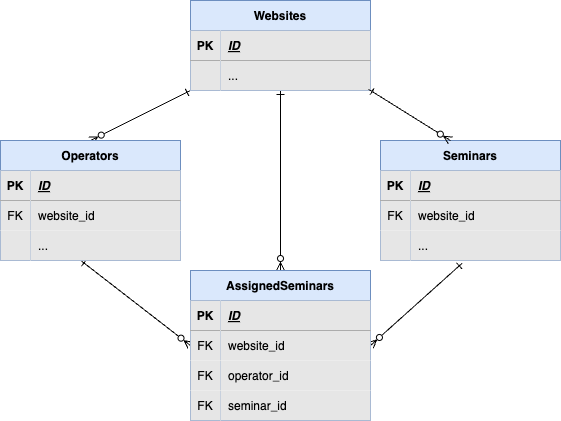
実装後の関係は以下の図のようになる想定です。
一般的な多対多の関係です。
テーブル設計
ここから実際にテーブルを作成するのですが、初めてなので何から手をつければいいのかわかりませんでした。
Techouse では、テーブルを作成する前にスキーマ表というテーブルの仕様をまとめた表を作成してレビューしていただき、問題なければ migration ファイルを作成するという進め方をしています。
以下のような表に作成したいテーブルの仕様をまとめます。

index...? exclude 制約...? unique 制約...?
見慣れない単語が並んでおり、ここに何を書けばいいのか全くわからなかったのでレビューをいただく上司に聞いてみました。
僕:「ここの制約って何を入れればいいんですか?」
上司:「そのテーブルが実際にどうやって参照されるかを考えて書けばいいよ!」
僕:「...はい。」
このテーブルがどうやって参照されるかを考えて、今回作りたい機能の仕様から以下の 2 パターンの参照方法があると考えました。
- 複数の選択したオペレータが担当する説明会を全件取得する
- ある 1 つの説明会の担当者を全員取得する
DB の index や unique 制約の役割について調べて、以下のようなスキーマ表を作成しました。
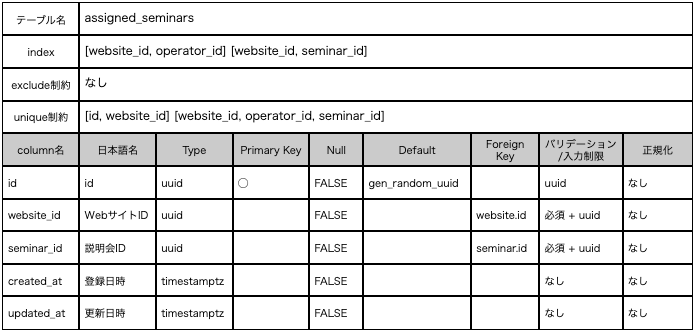
これで上司にレビューをいただいたところ、以下のようなレビューが返ってきました。
上司:「インデックスが二重で張られてるんじゃない?実際に想定される SQL 叩いて実行時間見てみて!」と。
僕:「...?」
正直、何を言っているのかわかりませんでしたが、とりあえず色々と調べてみることにしました。
調査開始
ここからは実際にテーブルを作成し、インデックスの張り方による実行計画の違いを確認します。
今回、二重にインデックスが張られているんじゃないかという指摘を受けたので、[website_id, operator_id] というインデックスに着目します。
以下の 5 パターンについて同じ SQL 文を実行して実行時間を確認します。
- 制約やインデックスなし
- ユニーク制約のみ
- インデックスのみ
- ユニーク制約とインデックス
- ユニーク制約のみ & 項目の順番を入れ替える
| No | ユニーク制約 | インデックス |
|---|---|---|
| 1 | なし | なし |
| 2 | website_id,operator_id,seminar_id | なし |
| 3 | なし | website_id,operator_id |
| 4 | website_id,operator_id,seminar_id | website_id,operator_id |
| 5 | website_id,seminar_id,operator_id | なし |
実際にテーブルを作成します。
ユニーク制約やインデックスは後から自由に追加や削除が可能なため、まずは制約なしでテーブルを作成しておきます。
-- テーブル作成 CREATE TABLE assigned_seminars ( id uuid NOT NULL DEFAULT gen_random_uuid(), website_id uuid NOT NULL, operator_id uuid NOT NULL, seminar_id uuid NOT NULL, created_at timestamptz NOT NULL, updated_at timestamptz NOT NULL, ) PARTITION BY HASH(website_id); -- RLS や Policy については省略 ...
テーブルを作成できたので、実際にデータを入れていきます。ここでは、最もデータ量が多い企業の 2 倍のデータ量で実験します。
担当者テーブルは全ての説明会に全てのオペレータが担当するという最悪ケースを考えて、オペレータ数 x 説明会数とします。
- オペレータ数: 400
- 説明会数: 150
- 担当者数: 60,000
また、実際に発行する SQL 文は以下です。
オペレータを複数指定してそのオペレータが担当しているセミナーを取得することを想定しています。
EXPLAIN ANALYZE SELECT s.* FROM seminars s JOIN assigned_seminars ass ON s.id = ass.seminar_id WHERE ass.website_id = <websiteID> AND ass.operator_id IN (<operatorIDs>);
実験結果
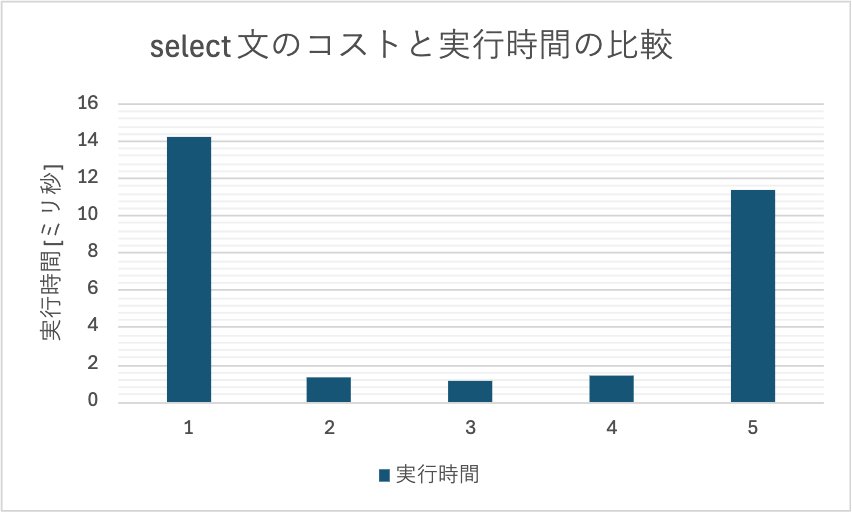
各パターンの実行計画を算出してまとめたグラフが以下です。
実行時間は 5 回同じクエリを実行した平均をとっています。
冒頭のグラフと同じものです。
考察
得られた実験結果から各パターンを比較して考察します。
まず、実行時間が非常に長い 1 と 5 からは、テーブルからデータを検索する時はインデックスが非常に大切だということがわかります。
また、ただ単にインデックスを張ればいいのではなく、実運用でどういう SQL が吐かれるのかを考えてその順番でインデックスを張らないといけないことがわかります。
2 と 3 の結果からは、実行時間に差はほとんどないことがわかります。このことから、ユニーク制約とインデックスは実行時間に対するパフォーマンスの差異がないことがわかります。
今回、レビューいただいた指摘で確認したかった 2 と 4 の比較についてですが、実行時間にほとんど差がないので、ユニーク制約はデータが一意であることに加え、ユニーク制約を宣言した順番で内部的にインデックスを張っていることがわかりました。
まとめ
上記の結果・考察から、レビューでいただいた指摘の意味がわかりました。
PostgreSQL ではユニーク制約を設定すると、その順番でインデックスが張られます。なので、別途インデックスを張ると二重でインデックスが張られてしまうんですね。
PostgreSQL の公式にもしっかりと記載されていました。
公式ドキュメント
"手作業で一意列に対しインデックスを作成する必要がないことには注意してください。これは、単に自動作成されるインデックスを二重にするだけです。"
-- PostgreSQL 公式ドキュメント
ところで...
結果の表から、インデックスを二重に張ってしまった時とそうでない時を比べても実行時間が変わらないのであれば、二重に張っても問題ないんじゃないかと思ってしまいますが、全くそんなことはありません。
読み取る時は特に問題にはなりませんが、データを新しく書き込む時に問題になります。
データを新規追加するときには、合わせてインデックスも更新する必要があります。
なので、インデックスが張られていればその分データの挿入コストは高くなってしまいます。
これについても気になったので、実際に SQL を叩いてみて実行時間の差を見てみることにしました。
あるセミナーに担当者を新たに 5 人追加するパターンを考えます。
発行する SQL は以下です。
EXPLAIN ANALYZE INSERT INTO assigned_seminars (website_id, operator_id, seminar_id, created_at, updated_at) VALUES (<websiteID>, <operatorID1>, <seminarID>, now(), now()), (<websiteID>, <operatorID2>, <seminarID>, now(), now()), ... (<websiteID>, <operatorID5>, <seminarID>, now(), now()),
分析結果
こちらも各パターンにて結果を出してみました。
先ほどと同様に、実行時間は 5 回同じクエリを実行した平均をとっています。

考察
得られた実験結果から、二重でインデックスを張ってしまった時は実行時間が伸びてしまうことがわかりました。
今回の実験ではインデックスが複雑でなかったため、実行時間に大きな差は見られませんでした。しかし、項目数が多いインデックスや複数のインデックスがある場合は、実行時間に顕著な差が生じると考えられます。
assigned_seminar テーブルは項目数が非常に少ないので上記のような事象を試すのには不向きですが、試しに無理やり不必要なインデックスを張って先ほどと同じクエリを実行してみました。
結果は実行時間が 1.163ms となりました。インデックスが複雑であればあるほど想定通り挿入コストが高いことがわかりました。
さいごに
インデックスはデータベースを理解する上で必須の概念です。特にデータ数が運用していく中で非常に多くなるテーブルや、ユーザーからの参照頻度が高いテーブルに対しては気をつけなくてはならないです。
今回初めてテーブル設計を経験して、インデックスについての理解が深まりました。
これから自分でテーブルを設計する時や、他人が設計したものをレビューするときは今回学んだことを活かせるようにしたいです。
Techouseでは、社会課題の解決に一緒に取り組むエンジニアを募集しております。 ご応募お待ちしております。