
こんにちは、株式会社Techouseのジョブハウスでエンジニアインターンをしているmiyatisです。本記事では、RubyKaigi 2025 1日目のYuichiro Kaneko (@spikeolaf) さんによるセッション、「Ruby's Line Breaks」について紹介させていただきます。
はじめに
Rubyを書いていると、どこで改行できるのか、迷うことがあると思います。例えば、以下の2つのコードを見てみましょう。
# コード1: 2つのメソッド呼び出し p 1 p 2
# コード2: 1つのメソッド呼び出し (1 + 2 の結果を表示) 1 + 2
コード1では、改行が文の区切りとして機能し、pメソッドが2回呼び出されます。 一方、コード2では、改行は無視され、1 + 2という1つの式として解釈されます。 なぜこのような違いが生まれるのでしょうか。
改行の原則
この疑問に対して、Tanaka Akira (@tanaka_akr) さんは次のように主張しています。
Ruby における改行による文の終了を説明するなら 「Ruby では原則的に文が終了できるところに改行があれば文が終了するが、いくつか例外がある。 例外1: (省略) ...」などとなるだろう。
引用元:https://x.com/tanaka_akr/status/1870679443376947467
いくつかの簡単な例で見てみましょう。
- 引数なしメソッド呼び出し: method_1 はそれ自体で完結した文なので、改行があれば文は終了します。
method_1 # ここで文が終了 arg # これは別の文(未定義のローカル変数またはメソッド呼び出し)
- 引数ありメソッド呼び出し: method_1 arg_1, はカンマで終わっているため、まだ文として完結していません。そのため、改行しても文は継続します。
method_1 arg_1, arg_2 # => method_1(arg_1, arg_2) と同じ
- 二項演算子: 1 + は文として完結していません。改行しても文は継続します。
1 + 2 # => 1 + 2 と同じ
- 単項演算子: - は文として完結していません。改行しても文は継続します。
- "str" # => -"str" と同じ
- 三項演算子:
cond ?やcond ? :tは文として完結していません。改行しても文は継続します。
cond ? :t : f # => cond ? :t : f と同じ
これらの例を見る限り、田中氏の主張は正しそうです。 しかし、Rubyのすべての文法において、本当にこの原則だけで説明できるのでしょうか。
Rubyは改行をどう処理しているのか: Lex Stateの登場
まず、Rubyはプログラムを機械が理解できるトークン列に分割します。これを行うのがレキサー (Lexer) です。例えば、数式 1 + 2 を 1、 +、 2の3つのトークンに分割します。
次に、分割されたトークン列を受け取り、それが文法として正しいかを判定するのがパーサー (Parser) です。
そして、Rubyにおける改行の扱いの鍵を握るのはレキサーです。Rubyのレキサーは、Lex State と呼ばれる内部状態に応じて、改行文字 \n を無視するか、あるいは意味のあるトークンとしてパーサーに渡すかを判断します。具体例を見てみましょう。
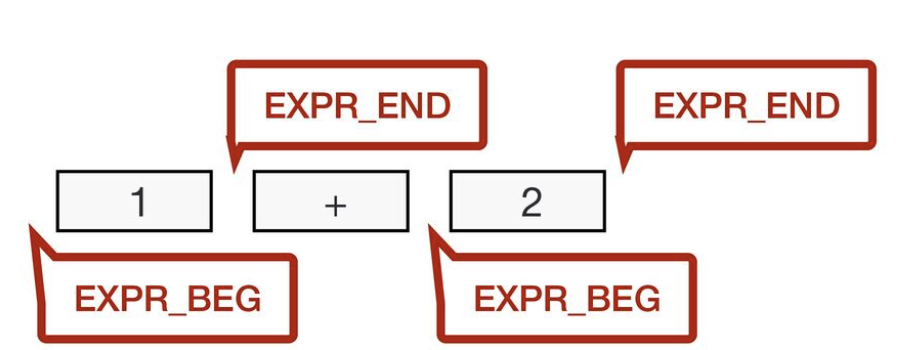
トークン 1 の手前ではLex Stateは EXPR_BEG (式の開始) です。トークン + の手前では、式が終了するため、EXPR_END (式の終了) に遷移します。
 引用元:SpeakerDeck
引用元:SpeakerDeck
このタイミングで改行が来た場合、EXPR_END の状態では、レキサーは改行を トークンとしてパーサーに渡します。よって、そこで文が終了します。そのため 1 \n + 2 は 1 と +2 という別々の文(後者は単項+演算子)として解釈されます。
 引用元:SpeakerDeck
引用元:SpeakerDeck
次に、EXPR_BEG の状態(例: 1 + の直後)では、レキサーは改行を 無視 します。よって、文が終了しないため、 1 + \n 2 は 1 + 2 と解釈されます。
 引用元:SpeakerDeck
引用元:SpeakerDeck
このようにRubyはLex Stateに応じて改行を無視するかを判断しています。
Lex Stateの複雑さ:「カオスへの扉」
一見すると合理的に見えるLex Stateですが、その挙動は非常に複雑怪奇です。あるコミッターは「理解不能」、別のコミッターは「怖くて近寄りがたい」と語りました。また、発表者の金子氏がGeminiに詩的な表現を尋ねたところ、「パーサーの深淵に潜む、混沌(カオス)への扉」といった表現が返ってきたほどです。
なぜこれほど複雑なのでしょうか。
- パーサーとレキサーの密結合: 本来独立しているべきパーサーとレキサーが、Lex Stateを通じて密接に連携しあっているため、全体像の把握が困難です。
- 文脈依存: あるトークンが、文脈によって二項演算子や単項演算子になり、それぞれで期待されるLex Stateの遷移が異なる可能性があります。
- 状態の多重定義: 1つのLex Stateフラグ が、改行の無視/発行だけでなく、演算子の解釈など、複数の目的で使われているため、変更の影響範囲を予測するのが難しいのです。
これらの複雑さは、Rubyの改行に関する統一的な原則を見出す上で大きな障壁となっていました。
Lex Stateのモデル化:カオスに秩序を
金子氏はこの「カオス」を克服するため、Lex Stateの挙動をモデル化し、文法やオートマトンという秩序だったシステムに組み込む試みを行いました。Lrama(Ruby 3.3から導入されたパーサージェネレータ)を拡張し文法ファイル内でLex Stateの遷移を明示的に記述できるようにしたのです。
1 + 2をパースする際のLex Stateの遷移を明示的に記述すると以下のようになります。%lex-stateディレクティブ内で+トークンが入力されたら、EXPR_BEGに遷移することを示しています。また下側では、1 + 2 が 入力されたら、Lex Stateが EXPR_BEG に遷移することを示しています。
%lexer-state {
state EXPR_BEG;
state EXPR_END;
...
transitions {
`+` => EXPR_BEG # +が入力されたら、EXPR_BEGに遷移することを示す
...
}
}
expr : expr '+' expr
%ls{
EXPR_END # expr + expr が入力されたら、EXPR_ENDに遷移することを示す
}
これにより、特定のパーサー状態において、トークンに応じたLex Stateの遷移先が明確になりました。まさに、「カオス」の可視化です。
仮説の再検証と例外の発見
このモデル化された情報を用いて、最初の仮説「原則的に文が終了できるところに改行があれば文が終了する」を改めて検証します。
すると、いくつかの例外、つまり 文を終了できるのに改行が無視されるケース や 文を終了できないのに改行が挿入されるケース が見つかりました。
例外1: 文が完了可能でも改行が無視されるケース
- 無限範囲演算子
(..):(1..)は文として成立しますが、改行は無視されます。
(1..) # ここで文は完了できるが... .step(2) # 無視されて継続する => (1..).step(2)
- 無名引数
(*, **, &):*argsと**kwargs、&blockは文として成立しますが、改行は無視されます。
def m(*); end m * # ここで文は完了できるが... a # 無視されて継続する => m(*a)
def m(**); end m ** # ここで文は完了できるが... kw # 無視されて継続する => m(**kw)
def m(&); end m & # ここで文は完了できるが... b # 無視されて継続する => m(&b)
例外2: 文が完了不可能でも改行が挿入されるケース
- グローバル変数エイリアス:
alias $aは文として完了していませんが、改行が挿入されます。
alias $a # ここで文は完了していないが... $b # 改行が挿入されて、Syntax Errorが発生!
- BEGIN/END ブロック:
BEGIN {は文として完了していませんが、改行が挿入されます。
BEGIN { # ここで文は完了していないが...
puts "hello" # 改行が挿入され、Syntax Errorが発生!
} # (正しくは BEGIN { 改行 puts "hello" 改行 } )
結論:Rubyにおける改行の原則
これらの検証結果を踏まえると、Rubyにおける改行の原則は次のようにまとめられます。
- 原則 : 文が終了できる箇所に改行があれば、文は終了する。
- 例外
- 無限範囲演算子 (..) や無名引数 (*, **, &) の直後では、文が完了可能であっても改行は無視され、文は継続する。
- グローバル変数エイリアス (alias $gvar) や BEGIN/END ブロック定義の途中では、文が完了不可能であっても改行トークンが挿入される(結果として構文エラーになる場合がある)。
感想
普段何気なく使っているRubyの改行ですが、その仕組みに注目してみると、非常に面白い発見がありました。改行の解釈にはレキサーとパーサーの複雑な挙動が絡んでおり、それはまさに「カオスの扉」だなと感じました。このコードを解読して、LramaやPrismの開発に携わっているコミッターの方々は本当に化け物だと感じました。また、改行処理における原則と例外的なケースを知ることで、Rubyの言語仕様の奥深さに触れることができ、とても勉強になりました。なぜこのような例外が発生するのか、コードを追ってみたいです!
Techouseでは、社会課題の解決に一緒に取り組むエンジニアを募集しております。 ご応募お待ちしております。