
初めまして、株式会社Techouseでバックエンドエンジニアをしている本澤(mottei)と申します。本日は私の携わっているプロダクトであるクラウドハウス労務で利用されている分散プログラミングの技術について紹介します。
クラウドハウス労務について
分散プログラミングについて紹介する前に、私が開発しているクラウドハウス労務について、なぜ分散プログラミングが必要かの説明も兼ねて紹介します。
クラウドハウス労務は労務業務の電子化を推進するためのクラウドサービスです。人事労務担当と従業員との手続き機能・年末調整などの法定業務など様々な機能を持っており、企業の人事労務担当者と従業員とのやりとりを簡単に行うことができます。
これらのたくさんの手続きによって集められた大量の従業員データは、クラウドハウス労務のデータベースに格納されています。クラウドハウス労務は大企業が持つ基幹システムなどの別システムとの連携を想定しているため、データエクスポートに関わる機能が充実しています。
私は昨年、年末調整のプロジェクトを担当しており、年末調整で収集した情報のエクスポート機能のパフォーマンス改善などを行っていました。
分散プログラミング
上述したようにクラウドハウス労務では大規模なデータのエクスポートが多いプロダクトです。これらの処理をなるべく早く、なるべくサーバーへの負荷を少なく完了させることが必要となってきます。
そこで私たちはSidekiqを使ったジョブ実行を、複数台同時に並列実行させる分散プログラミングによって実現しています。
この記事における分散プログラミングの定義
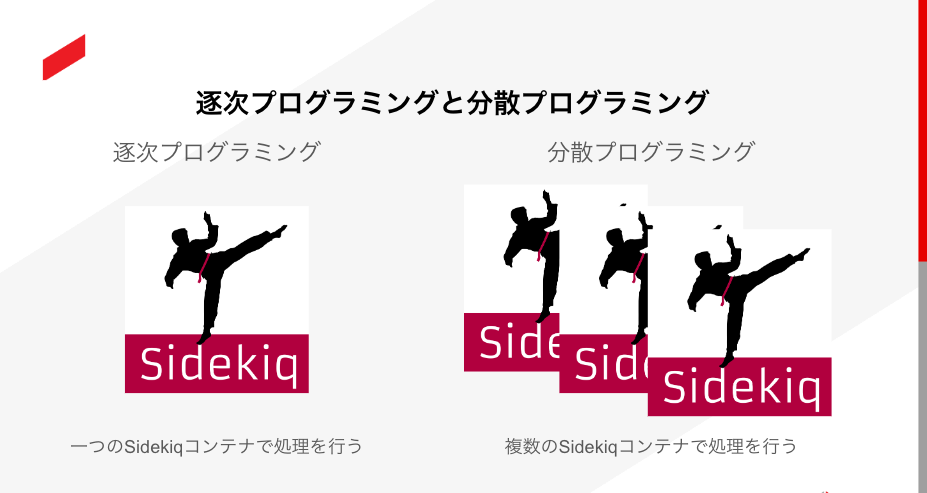
ひとえに分散プログラミングといっても指すものが明確ではないので、誤解がないように記事内での定義を述べておきます。分散プログラミングの定義は難しいですが、誤解を恐れずに一言で言うと、「複数のノードに分かれたプログラムが同時並行的に実行され、協調しながら1つの目的を達成するプログラミング手法のこと」です。
クラウドハウス労務ではコンテナの起動・管理にAWSのECS(Elastic Container Service)を利用しています。SidekiqもECSで管理されたコンテナ上で動いており、実行されているジョブの数によってコンテナ数を増減させられるようなインフラとなっています。したがって今回の分散プログラミングとは「ある目的を達成するために、複数のSidekiqサーバー(コンテナ)が同時に処理を行うことで全体のパフォーマンス、スケーラビリティを向上させるプログラミング手法」のこととします。
今回例にあげる機能
クラウドハウス労務の年末調整機能で収集したデータのエクスポート機能(以降「収集情報エクスポート」)を例として説明します。これは年末調整機能で収集した情報を1つのエクセルファイルに出力する機能です。
年末調整では本人に関する情報(生年月日や収入・障害者かどうかなど)・家族情報・保険情報・住宅ローン控除情報など従業員一人当たり収集するデータ量が多いです。さらに従業員数の多い企業では処理にかなり時間がかかってしまいます。
そこで、収集情報エクスポートの従業員データを取得する処理を並列して行うことで高速化を図ります。
登場するジョブ
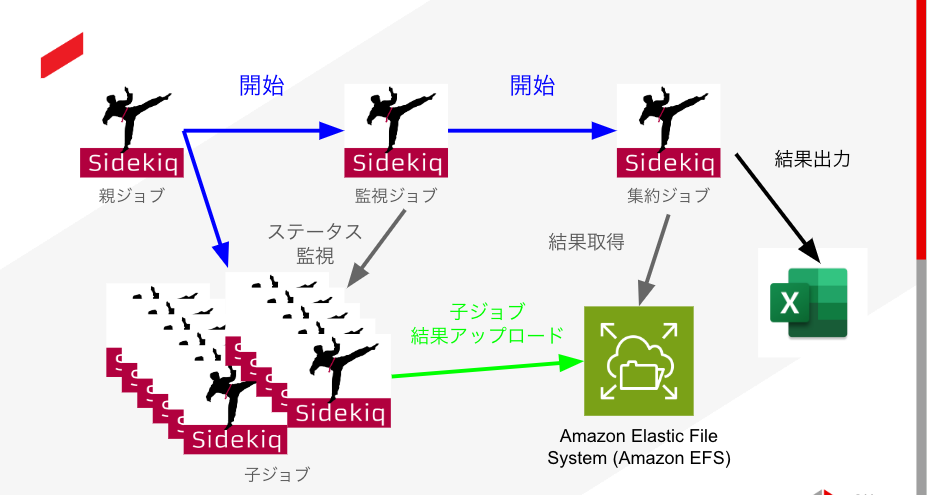
複数のコンテナでそれぞれのジョブが実行されますが、ジョブごとに処理内容が異なります。それぞれのジョブの責務を説明します。また「親ジョブ」や「子ジョブ」などの名称はクラウドハウス労務内で利用されている名称であり、分散プログラミングにおける用語ではありません。
- 親ジョブ
最初に1つだけ開始されるジョブです。子ジョブと監視ジョブを起動することが主な役割です。
収集情報エクスポートでは処理対象の従業員を取得し、それらを子ジョブに渡します。
- 子ジョブ
メインの処理を行います。収集情報エクスポートでは親ジョブから処理対象の従業員IDを受け取り、その従業員のデータを取得・整形します。処理対象の従業員の総数と子ジョブあたりに処理する従業員数の設定によって子ジョブの数は変動します。処理結果はEFSにアップロードします。
- 監視ジョブ
1つだけ起動され、子ジョブの進行状況を定期的にチェックします。全ての子ジョブが完了したら集約ジョブを起動します。
- 集約ジョブ
最後に1つだけ起動されます。子ジョブの処理内容をもとに最後のまとめ処理を行います。集約の必要がない類のジョブの場合は必要ありません。
収集情報エクスポートでは子ジョブの処理結果を集約し、1つのファイルにまとめて出力します。
処理の流れ
- 親ジョブの作成
- 親ジョブが子ジョブ・監視ジョブを開始
- 子ジョブで処理を行う
- 監視ジョブは定期的に子ジョブの進行状況を確認する。全て完了すると集約ジョブを起動
- 集約ジョブが子ジョブの実行結果をまとめて1つの大きなファイルを作成
- ジョブ完了
各ジョブの簡単な実装例
説明のためにかなり簡略化しています。
親ジョブ
出力対象となる従業員を取得し、子ジョブと監視ジョブを開始します。
# 1つの子ジョブあたりに処理する従業員数 EMPLOYEES_NUMBER_PER_CHILD_JOB = 100 def process_job(**arguments) parent_job_id = arguments[:parent_job_id] company = Company.find(arguments[:company_id]) # 出力対象となる従業員を取得する employees = company.employees.where(...) ActiveRecord::Base.transaction do # 子ジョブを開始する employees.pluck(:id).each_slice(EMPLOYEES_NUMBER_PER_CHILD_JOB) do |target_employee_ids| kick_child_job(parent_job_id, target_employee_ids) end # 監視Jobを開始する kick_monitor_job(parent_job_id) end end
子ジョブ
親ジョブから渡された従業員IDをもとにデータを取得します。取得結果はJSON形式にしてEFSにアップロードします。
def process_job(**arguments) company_id = arguments[:company_id] target_employee_ids = arguments[:target_employee_ids] result = export_nencho_employee_data(company_id, target_employee_ids) # EFSに入れる output = JSON.pretty_generate(result) upload_to_efs(output) end
監視ジョブ
子ジョブのステータスを定期的に監視します。監視の間隔はジョブが長ければ長いほど長くなるように調整します。
def process_job(**arguments) parent_job_id = arguments[:parent_job_id] company_id = arguments[:company_id] job = find_child_job(job_id) children_jobs = ChildJob.where(parent_job_id: parent_job_id) retry_count = 0 while # 子ジョブが全て完了するまで継続 sleep_second = sleep_duration(retry_count) # ループ回数によって秒数を増やしていく sleep(sleep_second) # 完了していないジョブを取得する not_completed_jobs = fetch_not_completed_job(children_jobs) # 完了していないジョブがなくなったら終了 break if not_completed_job.blank? retry_count += 1 end # 集約Jobを動かす kick_merge_job end
集約ジョブ
子ジョブを取得して結果ファイルを作成します。結果ファイル作成の処理は本筋とは逸れるので省略しています。
def process_job(**arguments) parent_job_id = arguments[:parent_job_id] company_id = arguments[:company_id] children_jobs = ChildJob.where(parent_job_id: parent_job_id) create_excel(parent_job, children_jobs) end
気をつける点
- 1つの子ジョブあたりにどれくらい処理をさせるか
分散プログラミングの大きな強みの1つにスケーラビリティがあります。コンテナ数を増やすことで並列数を増やし、大きな処理でも早く完了させることができます。
ただし、並列数を増やせば増やすほどデータベースへの負荷は高まります。固定スペックのデータベースを利用している場合、「処理を早く終わらせるためにコンテナ数を増やす → 大量のコンテナが一挙にデータベースにアクセス → データベースが急激な負荷に耐えられなくなる」といった流れで障害に発展する可能性があります。
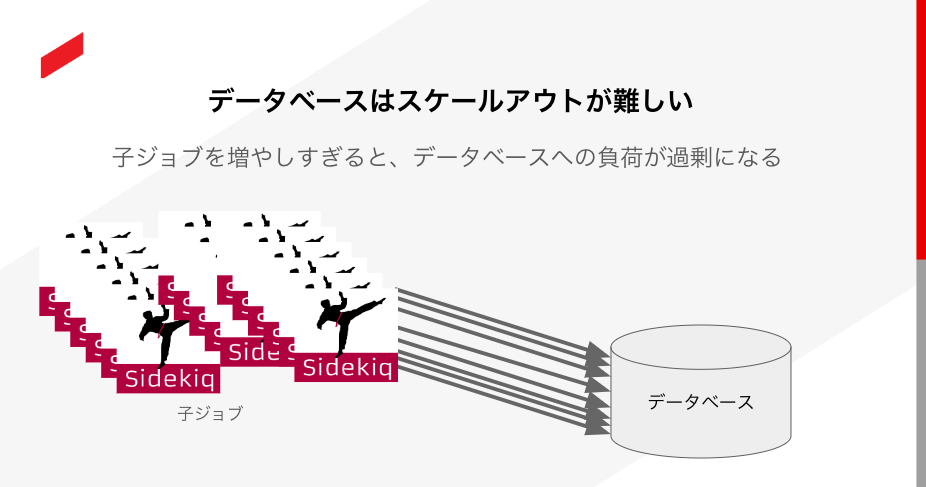
とはいえ並列数が少なくして1子ジョブあたりの処理数を増やすと、分散プログラミングによるメリットを受けられません。分散プログラミングを設計する際には「子ジョブはn秒以内に完了する」といった目標を設定しておくとよいでしょう。
- インフラの予期せぬ障害に備えること
ジョブが大量に作成されるので、それぞれが正常に動作しているかの管理は必要です。例えば、ECSの障害により子ジョブを実行しているコンテナが強制終了された場合、監視ジョブがもう動いていないジョブを待ち続けてしまいます。結果として監視ジョブが永遠に終わらないといったことが起こる可能性があります。アプリケーションのエラーだけではなく、インフラの予期せぬ障害に備えることが必要です。
- ジョブ同士の通信の仕方
1つの処理を分散させている以上、逐次プログラミングでは必要ないコンテナ同士の通信が必要となってきます。監視ジョブによる子ジョブのステータス監視、子ジョブによる処理結果アップロードや集約ジョブの処理結果取得などがそれにあたります。
これらの処理が重くなるようでは分散させるメリットがなくなってしまいます。クラウドハウス労務では子ジョブと集約ジョブのファイル通信にEFSを利用することでオーバーヘッドを減らしています。
- そもそも分散させるべきか
ここまで散々分散プログラミングについて述べてきましたが、分散プログラミングはジョブのパフォーマンス改善の銀の弾丸ではありません。そこまで規模の大きくない処理ならばむしろ分散させず、基本的な高速化手法でより簡単に解決できます。分散プログラミングはパフォーマンス改善の手段の1つでしかないことを認識しておくことは重要です。
最後に
クラウドハウス労務で利用しているRuby on Railsでの分散プログラミングについて説明してきました。Ruby on Railsでの分散プログラミングはインターネット上に例が少ないため、参考になれば幸いです。また、「自分たちはこうやって分散プログラミングやってます!」みたいな例があればコメントなどで共有いただけると嬉しいです。