
Techouseの「エンジニア基礎勉強会」とは
Techouse では「基礎勉強会」と称して2週間に1回、わたしが OS・ネットワーク・データベース・ハードウェア・セキュリティ・システムアーキテクチャなどをお話する勉強会を開催しています。
講師は私ひとり、資料を準備するのも私ひとり、動画を収録して YouTube Live で社内向けに配信する作業も私ひとりでやってます。
参加は任意ですが、社内のメンバー (社員・インターン生・業務委託でご参画いただいている方) の多くの方が参加してくれています。先日の RubyKaigi 2024 に参加してくれたメンバーもほとんどがこの勉強会に参加し、基礎的な知識をもった上でセッションへ臨んでくれました。
開催履歴
これまでの開催履歴はこんな具合です。
見ていただくとわかる通り、ほんとうに基礎的な内容を1個ずつやっているということがわかるかと思います。
- 前提知識(1) - 2進数・8進数・10進数・16進数
- 前提知識(2) - シェルとエディタ
- 情報処理産業の歴史 (前半)
- 情報処理産業の歴史 (後半)
- いきなりネットワークプログラミング
- UNIX ファイルI/Oプログラミング
- 文字コードで一生困らない
- ネットワーク(1) 入門未満編
- ネットワーク(2) インターネットワーキング編
- ネットワーク(3) エンドツーエンド原理編
- ネットワーク(4) HTTP一歩手前編
- ネットワーク(5) HTTPその1
- ネットワーク(6) HTTPその2
- ネットワーク(7) Eメール
- OS(1) ノイマン型コンピュータからマルチタスクOSまで
- OS(2) カーネル編 (システムコール・プロセススケジューリング)
- OS(3) ユーザランド編<前半> (プロセス・ライブラリ)
- OS(4) ユーザランド編<後半> ファイルシステム、リソース保護、マルチユーザ
- OS(5) コンテナ仮想化
- LPIC/LinuC/LFS 学習環境構築
- データベース(1) ACID
- データベース(2) 分離性
- データベース(3) 分散トランザクション
- データベース(4) 永続性
- データベース(5) 論理データモデリング
- データベース(6) 物理データモデリング
- データベース(7) インデックス
- データベース(8) キャパシティ/その他
- オブジェクト指向(1) 構造化プログラミング
- オブジェクト指向(2) オブジェクト指向 <下から見る>
- オブジェクト指向(3) オブジェクト指向 <上から見る>
- オブジェクト指向(4) デザインパターン
- アーキテクチャ(1) AWS の設計思想を知ろう
- アーキテクチャ(2) AWS Well-Architected Framework その1
- アーキテクチャ(3) AWS Well-Architected Framework その2
- アーキテクチャ(4) AWS のコストモデルを一気見する
- アーキテクチャ(5) AWS Well-Architected Framework その3
- アーキテクチャ(6) AWS Well-Architected Framework その4
- アーキテクチャ(7) CI/CD
- アーキテクチャ(8) SRE (Site Reliability Engineering)
- アーキテクチャ(9) Techouseにおける実装
- セキュリティ(1) セキュリティの基本
- セキュリティ(2) 暗号技術入門
- セキュリティ(3) 暗号技術基礎
- セキュリティ(4) 暗号技術実用
- セキュリティ(5) PKI
- システム設計 (概論)
- システム設計 (機能設計)
- システム設計 (攻めた設計)
- 半導体
- 時計・時間・日付
- 設計思想の話 + オープンソース入門
なんでこんな勉強会をやるのか
現代のプログラミングは、非常に高度な抽象化の上に成り立っています。わたしたちは、多くの言語処理系・フレームワーク・ライブラリなどを開発してきた偉人たちの肩の上に乗って、仕事をしています。
おかげで OS やメモリの存在、ネットワークの仕組みを意識しなくともそれなりの機能が作れるようになりました。これは、喜ばしき状況ではあります。
しかしながら、言語処理系・フレームワーク・ライブラリを作るとか、計算量を意識しなければ実現し得ないようなプロダクトを作りあげるためには、巨人の肩の上に乗せてもらっているだけでは不可能です。
その肩の下には、Qiita や Stack Overflow をめくっているだけでは絶対にたどりつけない世界がそこにあります。一定以上の大きなもの、一定以上の複雑なもの、一定以上の高速なもの。そういったものを作るためには、やはり巨人とならねばなりません。
そういったものを作れる人を養成したいのです。
Techouseでは、そのために基礎勉強会を開催しています。
サンプルを公開します
今回はお試し的に、勉強会の内容を公開してみます。
- データベース(1) ACID
- データベース(2) 分離性
ご笑覧くださいますと幸いです。
データベース(1) トランザクション <前編: ACID>
用語に注意
「データベース」という言葉を使うときに、
- 「単なるデータの集合」
- 「データが整理されて取り出しやすい形で保存されたもの」
(例: 郵便番号データベース) - 「データを整理して保管し、SQL文を使ってデータを保存・取り出しできるプログラム」
(例: MySQL とか PostgreSQL とか)
と、3通りの用法があります。ここでは厳密に区分するため、
- 2. のことを「データベース」、
- 3. のことを「データベース管理システム
(= DBMS = DataBase Management System)」
と呼ぶことにします。
PostgreSQL とか MySQL とか Oracle Database とか Microsoft SQL Server とか Microsoft Access とか Redis など、2. の「データベース」を扱うソフトウェアのことを「DBMS」と呼びます。
「えーっ、全部一緒じゃない?」と思われるかもしれませんね。
しかし、定義について厳密である必要があるから、そうしているのです。
ソフトウェアエンジニアにとって、定義に厳密であることというのは美徳の一つです。
優秀なソフトウェアエンジニアはみんな、用語の定義に対して常に厳密です。
みなさんも、用語の定義に関しては常に厳密であるようにしてください。
でも、やりすぎると、単なる嫌なヤツになってしまうので気をつけてください。
同業者同士にとどめましょう。
そして、友人・家族などに対して厳密な言葉の定義を求めないようにしましょう。
データ不整合あるある
たとえば、銀行口座を保管する RDB を考えてみます。
Aさんの口座には1000円が入っているとします。
Bさんの口座には2000円が入っているとします。
AさんからBさんの口座に500円を振り込むとします。
それと同時に、BさんからAさんの口座に1200円を振り込むとします。
この処理の結果としては、
「Aさんの残高が1700円、Bさんの残高が1300円」となるのが正しいはずですね。
ここでの、
「AさんからBさんの口座に500円を振り込む」処理をプログラム1、
「BさんからAさんの口座に1200円を振り込む」処理をプログラム2とします。
プログラム1・2は、
「振込元口座」、「振込先口座」の順に残高を取得し、
「振込元口座」から金額を減らして、「振込先口座」の金額を増やす、
という順に処理するものとします。
実行タイミングがまったく重ならなければ問題ありません。
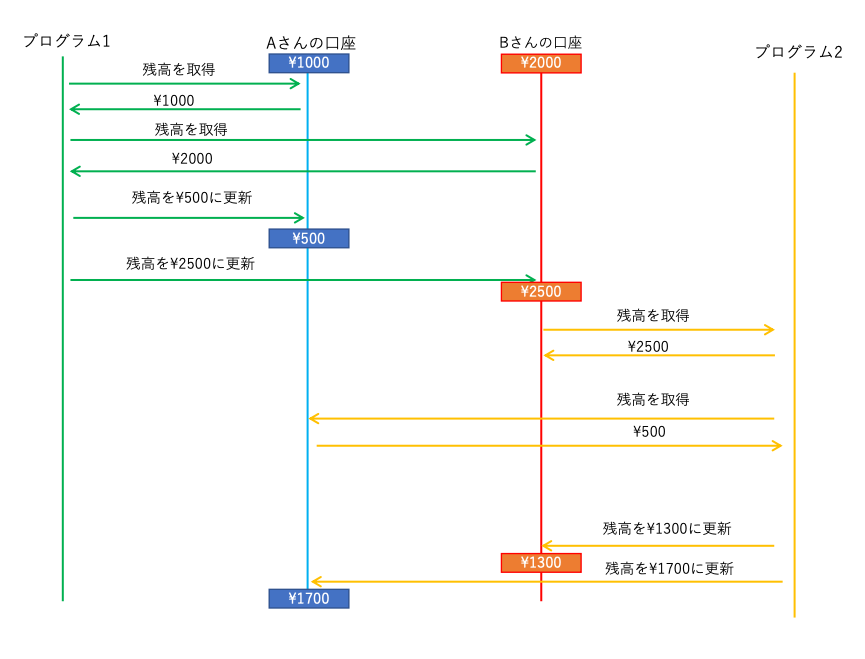
たとえば 1・2 の順で実行したとしたら、シーケンス図ではこうなります。
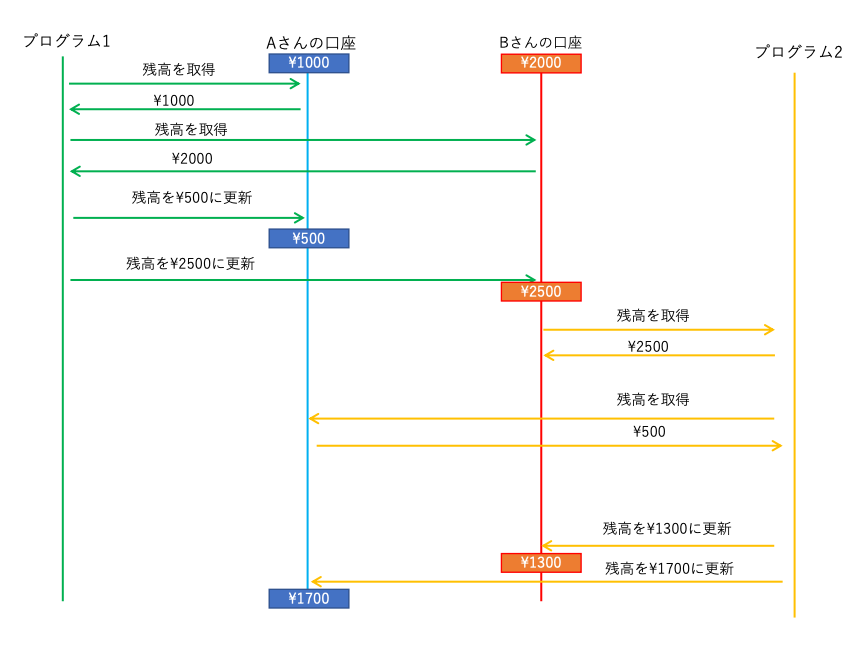
しかし同時に実行してしまうと、
Aさんの残高が2200円・Bさんの残高が800円、となってしまったり、
Aさんの残高が500円・Bさんの残高が2500円、となってしまったり、
Aさんの残高が1700円・Bさんの残高が2500円、となってしまったり、
Aさんの残高が1700円・Bさんの残高が800円、となってしまったり、
Aさんの残高が500円・Bさんの残高が1300円、となってしまったり、します。
なんでそうなると思いますか…?
じっくり考えてみましょう。
トランザクションとは
銀行口座のように、DB の読み書きには「これ以上切り離すことができない・切り離してはいけない単位」というものがあります。
それをトランザクションといいます。
前述の例でいうと、「残高の読み取りから更新まで」が、1件のトランザクションとなります。
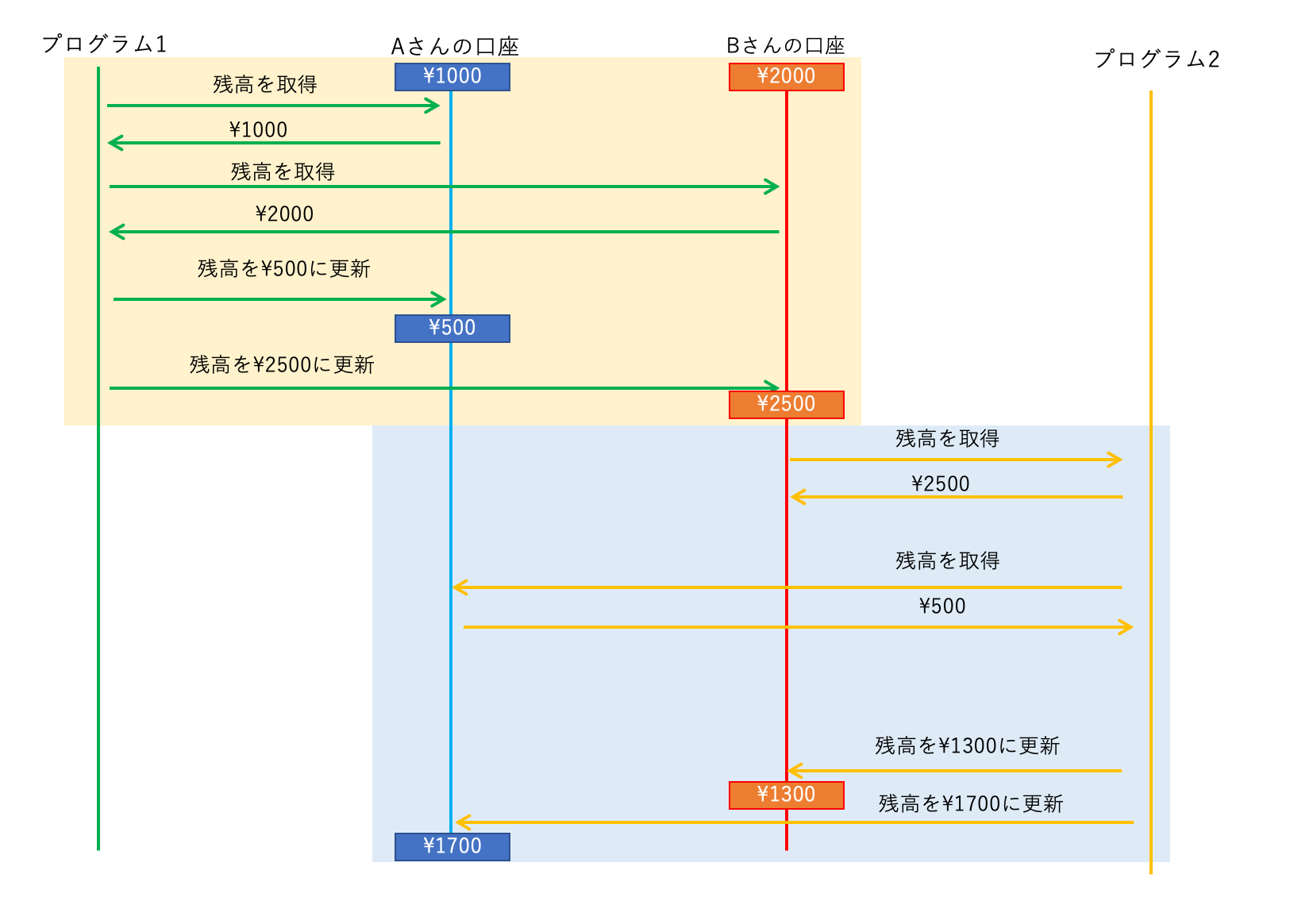
1つのトランザクションのなかの途中で他のトランザクションによる変更や読み出しが紛れ込むと、トランザクションの実行結果がおかしなことになってしまいます。これは困りますね。
トランザクションを扱うシステムにはどのような性質が必要なのでしょうか。
※トランザクションに関する一連の著作によって、彼はチューリング賞を受賞しています。
1970年代にジム・グレイが体系立って理論にまとめるまで、トランザクション処理は経験的・場当たり的に作られてきました。それが一気に理論立って説明できるようになり、トランザクション処理はそれより前に比べて一気にわかりやすく使えるようになったのです。
(……とはいっても、かなり難しいかもしれませんが……。)
そのジム・グレイの成果を、紹介していきましょう。
ACID
トランザクションを扱うシステムが満たすべき重要な性質4つをまとめて「ACID」といいます。
A: 不可分性 (Atomicity)
原子性ともいいます。
不可分性が保証されているというときには 「トランザクションのすべての処理が行われるか、まったく行われないか」が 保証されています。
たとえば下図のような不整合は起こりません。
もちろん「残高を¥500に更新」という処理の途中で、プログラムやDBMSが異常終了しても、
「残高が5円」とか「残高が50円」とかにならないようになっています。
プログラムの異常終了だけでなく、仮にハードウェアが故障しようとも、電源プラグがブチ抜かれようとも、中途半端な状態にはならないようになっているのです。
ちなみにコンピュータサイエンスの世界では、「これ以上細分化できない」という意味で 「アトミック」「原子的」という言い方をします。古代ギリシア語の ἄτομος (アトモス、これ以上分割できないもの) という言葉に由来する表現です。(原子の atom と同じ由来です。 )
C: 一貫性 (Consistency)
整合性ともいいます。
与えられたルールの範囲を逸脱する値が保存されないことを保証する、という意味になります。
たとえば、残高がマイナスになることはあり得ない、とします。
一貫性を保つというときには、仮にトランザクション終了時に残高がマイナスになったとしても、その結果が反映されないことが保証されます。
NOT NULL 制約なども一貫性を実現する機能の一部です。
I: 分離性 (Isolation)
独立性ともいいます。
トランザクション途中の状態が他のトランザクションから見えないことを指します。
分離性が保証されているとき、トランザクションは開始前か開始後のどちらかの状態しか 観測できなくなります。よって、下図のようなことは起こりません。
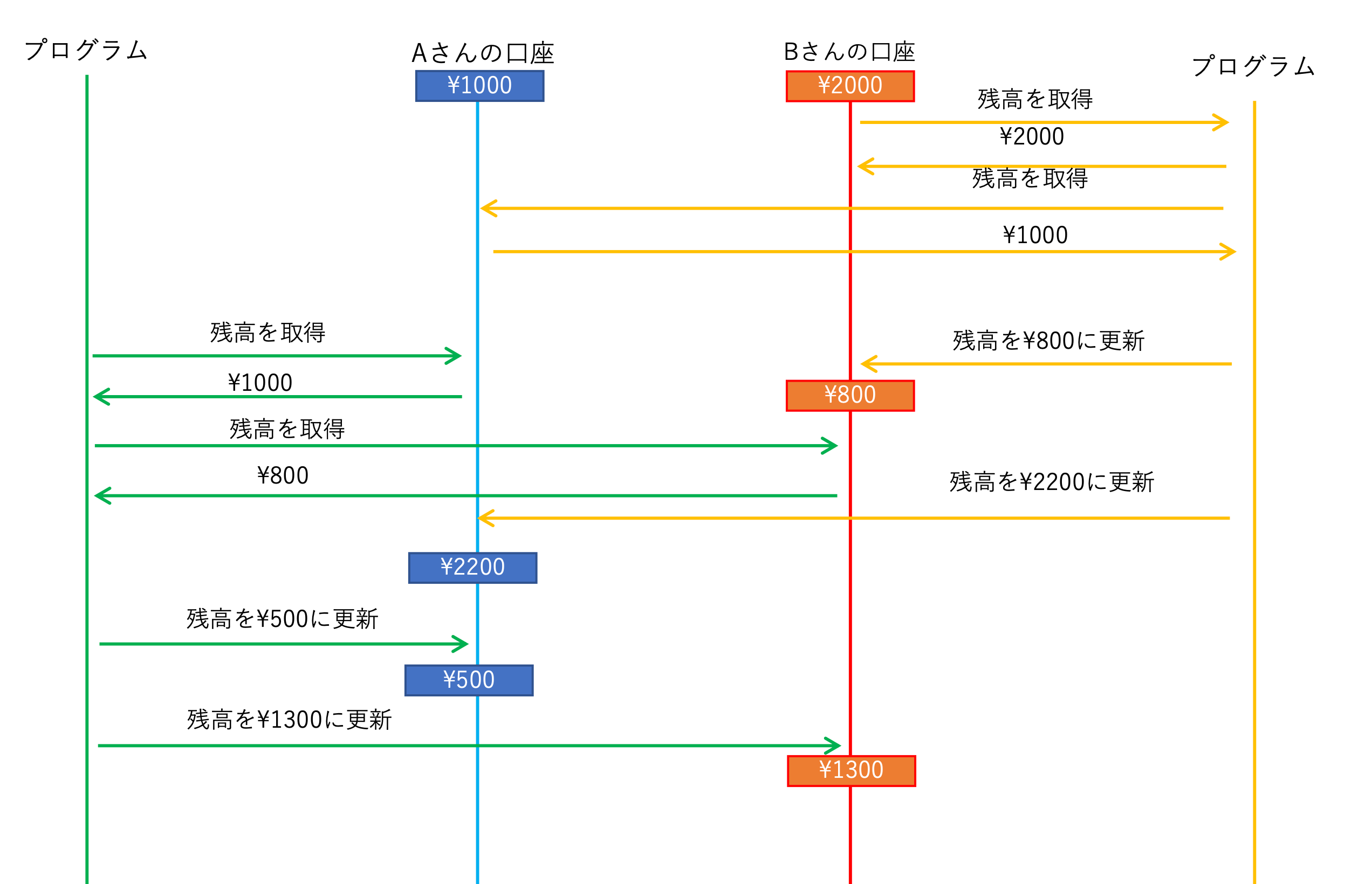
後で説明しますが、分離性は設定によって変わります。
D: 永続性 (Durability)
トランザクションの完了がユーザに通知された時点で、トランザクションによって反映されたデータは永続化 (保存され、揮発しない状態) されたことを保証します。
この4要素を ACID といい、
世の多くの RDBMS は ACID を 部分的に、あるいは条件つき で
サポートしています。
トランザクションの使い方
SQL文のレベルでは、トランザクションを、
START TRANSACTION; -- : COMMIT;
という構文で宣言できます。
簡略化して、
BEGIN; -- : COMMIT;
と書くこともできます。
この BEGIN 〜 COMMIT までの一連の操作のことを 「トランザクションブロック」といいます 。
トランザクションブロックの性質
トランザクションブロック内の処理には次のような性質があります。
- Atomicity: 不可分性
BEGIN文以後に実行した変更は、
COMMIT文を実行するまで反映されません。- プログラムの不正終了などにより
COMMIT文が実行されなかった場合には、元の状態に戻ります。
※このことをロールバックといいます。 COMMITを実行したくない場合には、ROLLBACKを実行することで明示的にロールバックを実行できます。
- Consistency: 一貫性
- あるトランザクションが
COMMITをすると、それよりも前にCOMMITされたデータの上にCOMMITされていることが保証されます。順序の入れ替わりは発生しません。 - 制約条件を満たせない場合には、
COMMIT文実行がキャンセルされ、すべての変更内容がトランザクション前の状態に戻ります。
- あるトランザクションが
- Isolation: 分離性
- トランザクション途中の変更内容は、他のトランザクションブロックからは見えません。仮に
COMMIT実行の途中であったとしてもです。(※この動作は設定で変わります。) - トランザクション中に適用した変更を他のトランザクションから見ようとした場合には、
COMMITが完了するまで、読みだしが待たされる場合があります。(この動作もは設定で変わります。)
- トランザクション途中の変更内容は、他のトランザクションブロックからは見えません。仮に
- Durability: 永続性
COMMIT文実行完了後、プロンプトが返ってきたら、変更内容が DB に反映されたことが保証されます。
PostgreSQL の CLI クライアント (psql) の場合は、明示的にトランザクションブロックを宣言しない場合 (= BEGIN と COMMIT を省略した場合) 、
1行の SQL 文が1つのトランザクションブロックとなります。
たとえば、
UPDATE INTO users(email) VALUES('example@example.com');
という1行を実行した場合には、
BEGIN; UPDATE INTO users(email) VALUES('example@example.com'); COMMIT;
を実行したのと同じ意味になります。
実際にやってみる
ここでは PostgreSQL を利用します。
finch を使って、コンテナ内に PostgreSQL を起動しましょう。
(finch の部分を docker や nerdctl に置き換えても実行できます。ご使用のコンテナ環境に合わせて読み替えてください。)
$ finch run --name postgres \ -e POSTGRES_PASSWORD=password \ -e POSTGRES_INITDB_ARGS="--encoding=UTF8 --no-locale" \ -e TZ=Asia/Tokyo \ -p 15432:5432 \ -d postgres
(もし「すでに postgres はあるよ」というようなエラーメッセージが出たら、 finch rm -f $(finch ps -f name=postgres -q) を実行してから、再度上記のコマンドを実行してみてください)
ターミナルのウィンドウを2枚開いて、並べて、 1つめのウィンドウで psql コマンドを使って PostgreSQL のクライアントを起動します。
$ finch exec -it postgres /bin/bash $ psql -U postgres
2つめのウィンドウでも同様にします。
$ finch exec -it postgres /bin/bash $ psql -U postgres
では、さきほどの例のようにやってみるとしましょう。
左側をプログラム1 (Aさんの口座からBさんの口座に500円送る)、
右側をプログラム2 (Bさんの口座からAさんの口座に1200円送る)、
を実行するものとします。
では、銀行口座を表現するテーブルを作り、Aさんの口座とBさんの口座を作りましょう。
まずは DDL (= Data Definition Language = データ定義言語) を実行していきます。
BEGIN; CREATE TABLE accounts ( id serial PRIMARY KEY, name varchar NOT NULL, balance decimal NOT NULL, CONSTRAINT balance_not_minus CHECK (balance >= 0) ); INSERT INTO accounts(name, balance) VALUES ('A', 0), ('B', 0); SELECT * from accounts; COMMIT;
COMMIT する手前で、2つめのウィンドウから SELECT * FROM accounts; してみてください。
COMMIT するまでテーブルが存在しないことになっている、ということがわかることでしょう。
では、初期残高を設定しつつ、Atomicity (不可分性) と Isolation (分離性) を試してみるとしましょう。
下記の DML (Data Modification Language = データ変更言語) を実行しつつ、
1行実行するごとに、別窓で SELECT を実行してみましょう。
;↓左のウィンドウで実行 ; ↓右のウィンドウで実行 BEGIN; SELECT * FROM accounts; UPDATE accounts SET balance = 1000 WHERE name = 'A'; SELECT * FROM accounts; UPDATE accounts SET balance = 2000 WHERE name = 'B'; SELECT * FROM accounts; COMMIT; SELECT * FROM accounts;
トランザクションブロック内での変更途中の内容が別窓から見えないことが確認でき、
COMMIT したタイミングで変更が反映されました、かね?
SELECT * FROM accounts; id | name | balance ----+------+--------- 1 | A | 1000 2 | B | 2000
「 COMMIT するまで見えない」というわけなので、
つまり、こういうことになります。
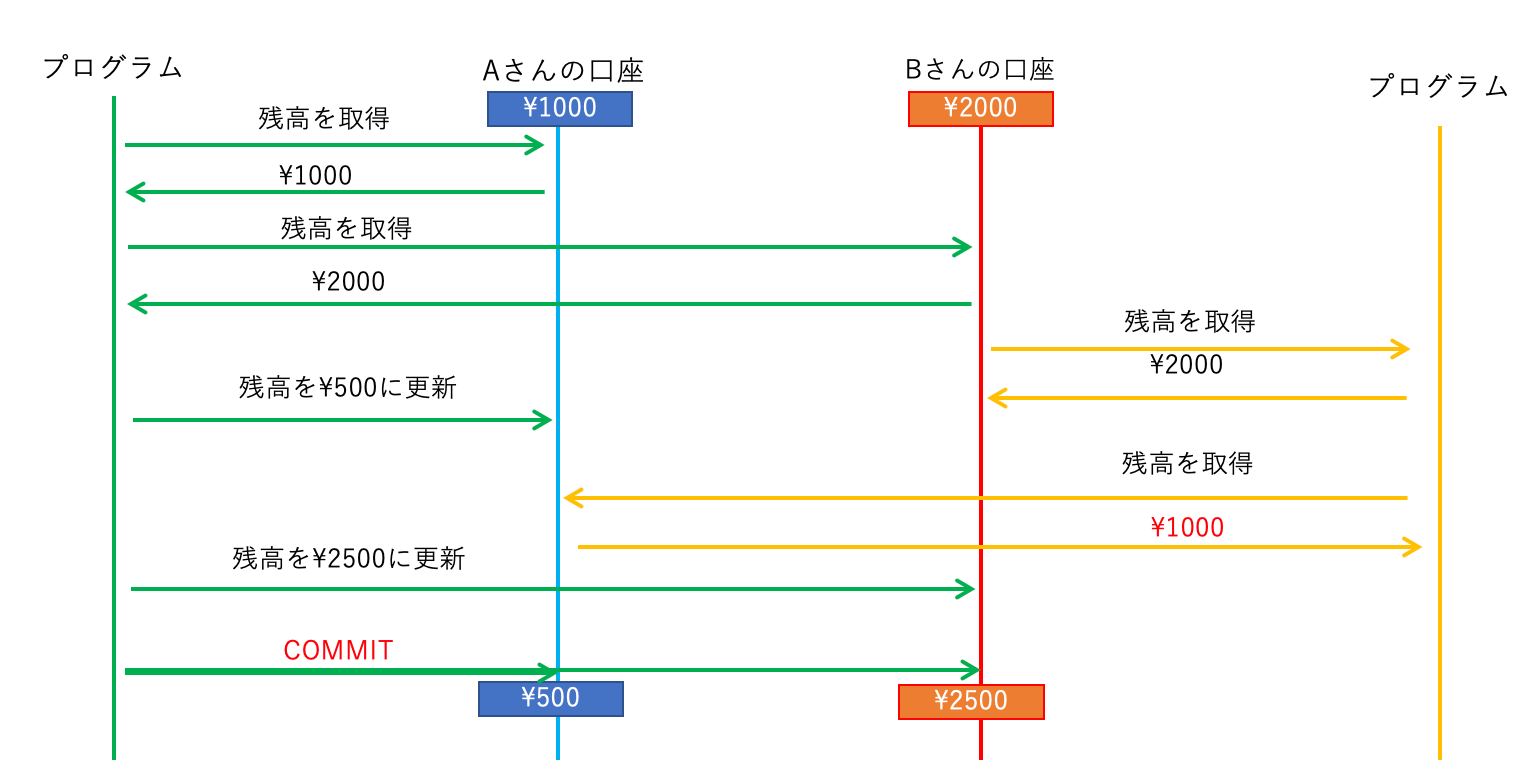
では、ロールバックも試してみましょう。
Aさんの残高をゼロにして、ロールバックしてみます。
;↓左のウィンドウで実行 ; ↓のウィンドウで実行 BEGIN; UPDATE accounts SET balance = 0 WHERE name = 'A'; SELECT * FROM accounts; SELECT * FROM accounts; ROLLBACK; SELECT * FROM accounts;
無事ロールバックされましたかね?
続いて、Consistency (整合性) を見てみましょう。
↓左のウィンドウで実行 BEGIN; UPDATE accounts SET balance = -1 WHERE name = 'A'; UPDATE accounts SET balance = NULL WHERE name = 'A';
ほら、はじかれましたでしょ?
そして、いったん COMMIT されたら Durability (永続性) によって保存されており、元の状態に戻ることはありません。という、これが DBMS の ACID 特性です。
Rails とトランザクションブロック
Rails の場合、ActiveRecord::Base#transaction にブロックを渡すと、その前後が BEGIN 〜 COMMIT で囲まれトランザクションブロックとなります。
ActiveRecord::Base.transaction do # : end
よく下記のようなコードを書く人がいますが…
User.transaction do # : end
これは User クラスの親クラスである ApplicationRecord の親クラスである ActiveRecord::Base クラスの transaction メソッドを実行しているのと同義です。
トランザクションブロック内でロールバックを実行したい場合には、例外クラス ActiveRecord::Rollback を raise します。
ActiveRecord::Base.transaction do raise ActiveRecord::Rollback end
トランザクションブロックの利用
では、トランザクションブロックを使って銀行口座の更新処理をやってみましょう。
まず、初期状態にデータを戻します。
UPDATE accounts SET balance = 1000 WHERE name = 'A'; UPDATE accounts SET balance = 2000 WHERE name = 'B';
2つのウィンドウを横にならべて、左側がプログラム1、右側がプログラム2、になったとします。
(XXXX の部分は自分で必要な金額をセットしてください。)
さあ、やってみましょう。
↓左のウィンドウで実行 = プログラム1 (AからBへ500円振り込む) ↓右のウィンドウで実行 = プログラム2 (BからAへ1200円振り込む) BEGIN; -- Aの残高を調べる SELECT balance FROM accounts WHERE name = 'A'; -- Bの残高を調べる SELECT balance FROM accounts WHERE name = 'B'; BEGIN; -- Bの残高を調べる SELECT balance FROM accounts WHERE name = 'B'; -- Aの残高を調べる SELECT balance FROM accounts WHERE name = 'A'; -- Aの残高から500円減らす UPDATE accounts SET balance = XXXX WHERE name = 'A'; -- Bの残高を500円増やす UPDATE accounts SET balance = XXXX WHERE name = 'B'; -- Bの残高を1200円減らす (実行がまたされる) ※理由はあとで説明します UPDATE accounts SET balance = XXXX WHERE name = 'B'; COMMIT; -- Aの残高から1200円増やす UPDATE accounts SET balance = XXXX WHERE name = 'A'; COMMIT;
あくまでもプログラム1, 2になった気持ちで実行してみてください。
結果はどうですか?
次のような結果になったと思います。
↓左のウィンドウで実行 = プログラム1 (AからBへ500円振り込む) ↓右のウィンドウで実行 = プログラム2 (BからAへ1200円振り込む) BEGIN; -- Aの残高を調べる -> 結果は1000円 SELECT balance FROM accounts WHERE name = 'A'; -- Bの残高を調べる -> 結果は2000円 SELECT balance FROM accounts WHERE name = 'B'; BEGIN; -- Bの残高を調べる -> 結果は2000円 SELECT balance FROM accounts WHERE name = 'B'; -- Aの残高を調べる -> 結果は1000円 SELECT balance FROM accounts WHERE name = 'A'; -- Aの残高から500円減らす UPDATE accounts SET balance = 500 WHERE name = 'A'; -- Bの残高を500円増やす UPDATE accounts SET balance = 2500 WHERE name = 'B'; -- Bの残高を1200円減らす = 800円にする UPDATE accounts SET balance = 800 WHERE name = 'B'; COMMIT; -- Aの残高から1200円増やす = 2200円にする UPDATE accounts SET balance = 2200 WHERE name = 'A'; COMMIT;
図で表すとこのようになります。
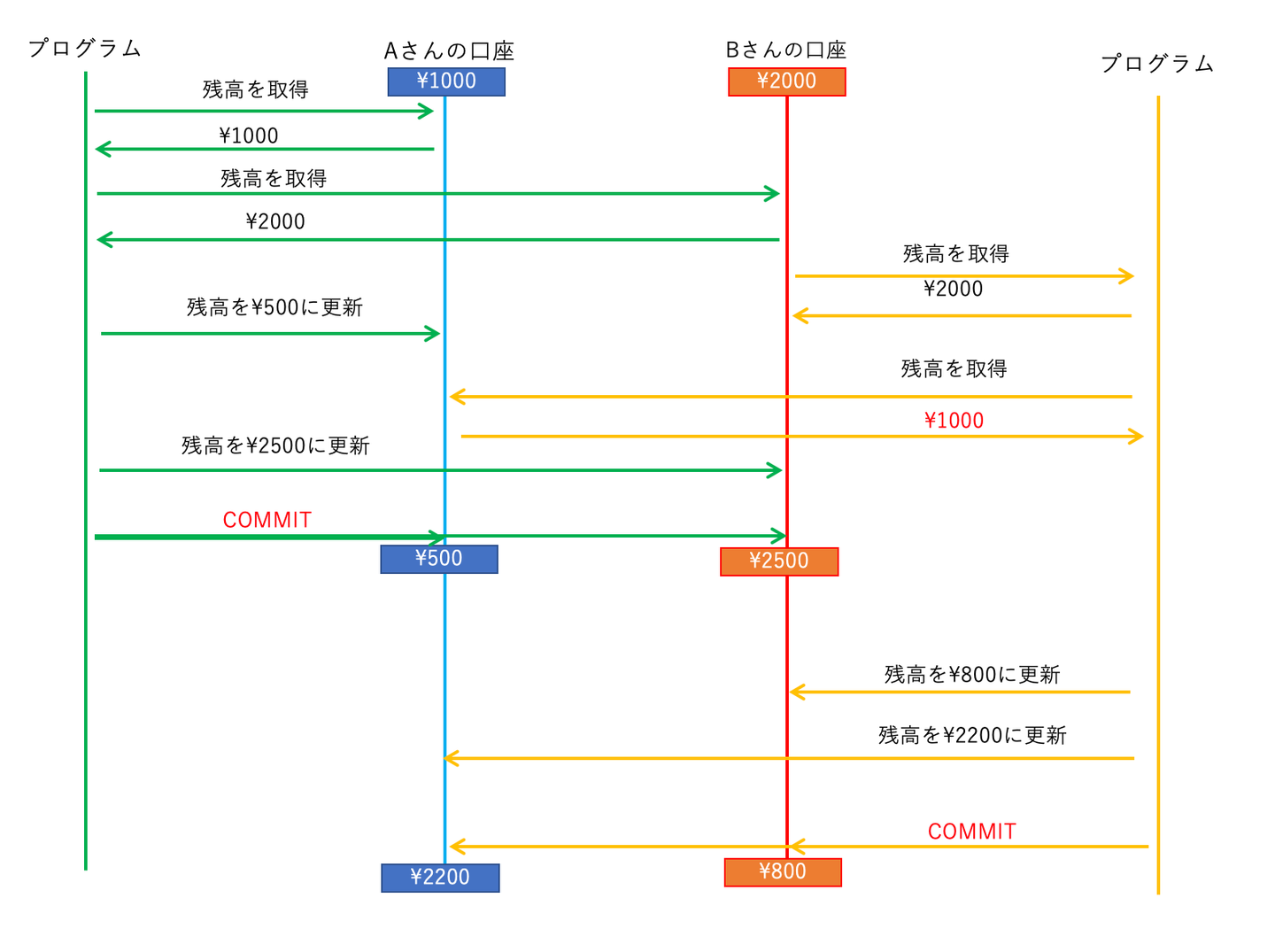
後から COMMIT したトランザクションブロックによって
前のトランザクションブロックが書いた値が、上書きされてしまいましたね。
これを「ロストアップデート」ないし「後勝ち (あとがち)」といいます。
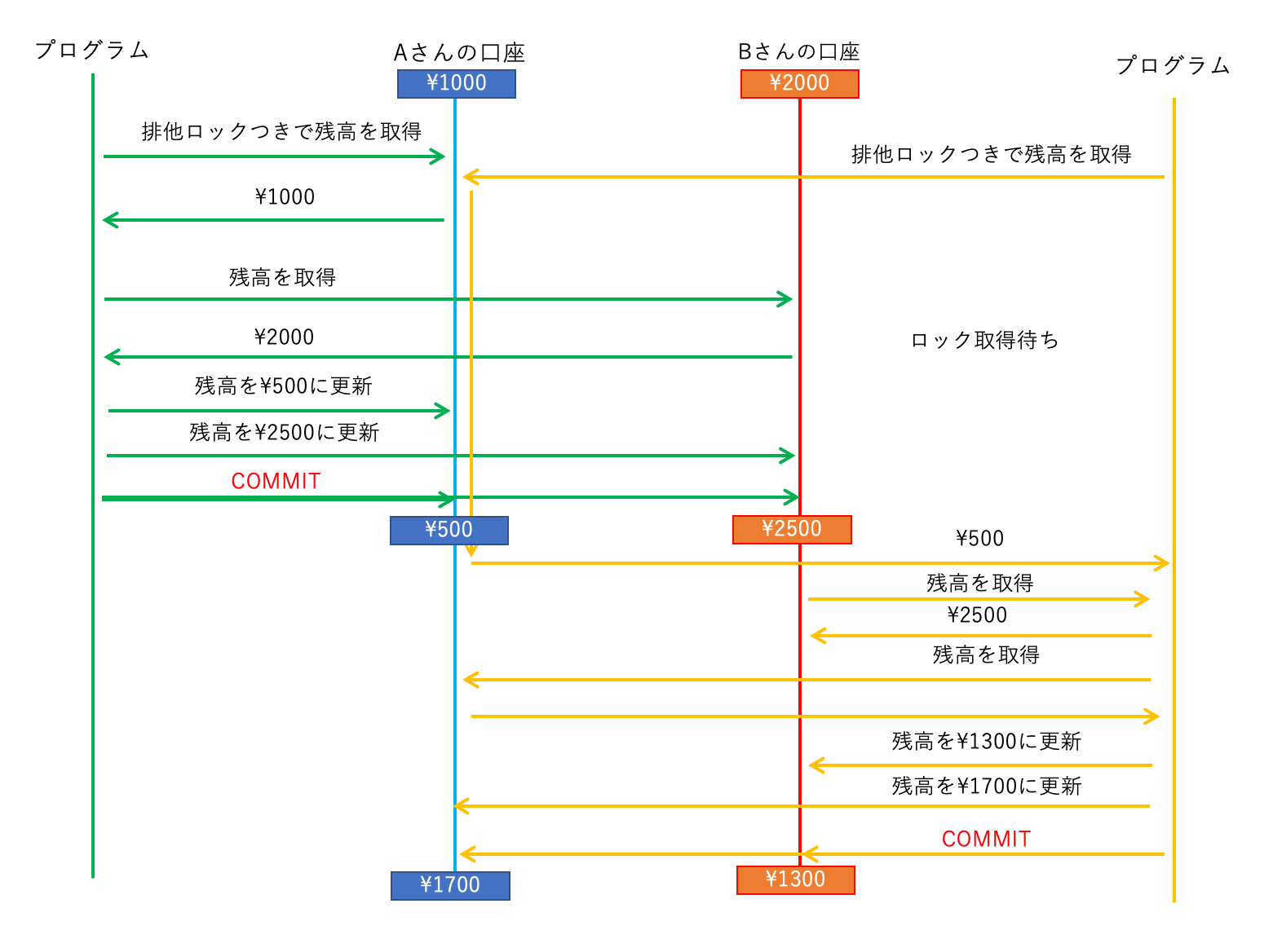
テーブルロック
LOCK TABLE 文をトランザクションブロック内で利用することによって、 COMMIT や ROLLBACK をするか UNLOCK TABLE 文を利用するまでテーブルへの読み書きをブロックできます。
下記のSQL文のように順番に実行してみてください。
↓左のウィンドウで実行 = プログラム1 (AからBへ500円振り込む) ↓右のウィンドウで実行 = プログラム2 (BからAへ1200円振り込む) BEGIN; BEGIN; -- accounts テーブルの読み書きをロックする LOCK TABLE accounts IN EXCLUSIVE MODE; -- accounts テーブルの読み書きをロックする -> またされる LOCK TABLE accounts IN EXCLUSIVE MODE; -- Aの残高を調べる SELECT balance FROM accounts WHERE name = 'A'; -- Bの残高を調べる SELECT balance FROM accounts WHERE name = 'B'; -- Aの残高から500円減らす UPDATE accounts SET balance = XXXX WHERE name = 'A'; -- Bの残高を500円増やす UPDATE accounts SET balance = XXXX WHERE name = 'B'; COMMIT; -- Bの残高を調べる SELECT balance FROM accounts WHERE name = 'B'; -- Aの残高を調べる SELECT balance FROM accounts WHERE name = 'A'; -- Bの残高を1200円減らす UPDATE accounts SET balance = XXXX WHERE name = 'B'; -- Aの残高から1200円増やす UPDATE accounts SET balance = XXXX WHERE name = 'A'; COMMIT;
LOCK TABLE accounts IN EXCLUSIVE MODE; は、テーブルに対して
「排他的ロック (Exclusive Lock)」をかける命令です。
排他的ロックを取得している間、
他のトランザクションブロックからの SELECT/UPDATE/INSERT/DELETE や
ロック取得が待たされます。
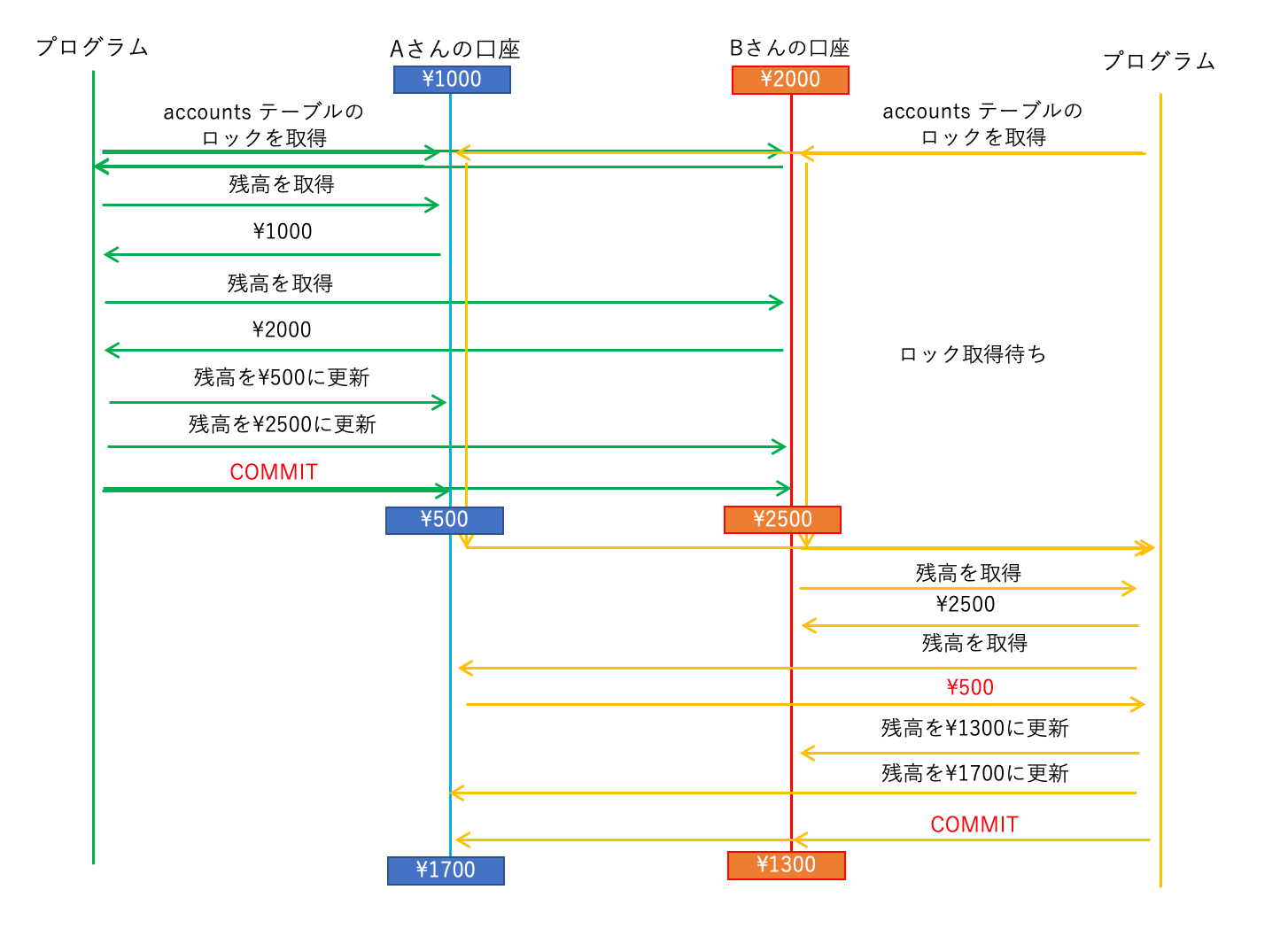
「テーブル単位」でロックを取得するため、 これを「テーブルロック」といいます。
Rails でテーブルロックを使うには、 ActiveRecord::Base.connection を使い、DB に直接 SQL 文を実行します。
ActiveRecord::Base.connection.execute('LOCK accounts IN EXCLUSIVE MODE')
テーブルロックはわかりやすく、非常に便利ではあるのですが、
Aさん・Bさん以外の口座の読み書きも止まってしまいますのでパフォーマンスが悪くなります。
楽天銀行は約1000万口座、ゆうちょ銀行は1億2000万口座以上を保有しているのだそうです。
仮にテーブルロックを使っていると、たった1つの口座の出し入れのたびに他の1億以上の口座が待たされるということになります。これはつらい。
というわけで、大きなシステムでは、めったにテーブルロックは使いません。
では、またいったんデータをリセットしましょう。
BEGIN; UPDATE accounts SET balance = 1000 WHERE name = 'A'; UPDATE accounts SET balance = 2000 WHERE name = 'B'; COMMIT;
行ロック
「必要な行だけをロックする」ということをしたくなりますよね。
そういうときには SELECT ... FOR UPDATE 文を使うことで、その SELECT 対象の行のみをロックでき、
COMMIT / ROLLBACK するまでその行に対する読み書きをブロック(=待たせる)できます。
やってみましょう。
↓左のウィンドウで実行 = プログラム1 (AからBへ500円振り込む) ↓右のウィンドウで実行 = プログラム2 (BからAへ1200円振り込む) BEGIN; BEGIN; -- Aの残高を調べる SELECT balance FROM accounts WHERE name = 'A' FOR UPDATE; -- Bの残高を調べる SELECT balance FROM accounts WHERE name = 'B' FOR UPDATE; -- Bの残高を調べる SELECT balance FROM accounts WHERE name = 'B' FOR UPDATE; -- Aの残高を調べる SELECT balance FROM accounts WHERE name = 'A' FOR UPDATE; -- Aの残高から500円減らす UPDATE accounts SET balance = XXXX WHERE name = 'A'; -- Bの残高を500円増やす UPDATE accounts SET balance = XXXX WHERE name = 'B'; COMMIT; -- Bの残高を1200円減らす UPDATE accounts SET balance = XXXX WHERE name = 'B'; -- Aの残高から1200円増やす UPDATE accounts SET balance = XXXX WHERE name = 'A'; COMMIT;
この順序通りに実行してみてください。すると…
ERROR: deadlock detected
と出たはずです。
このとき、2つのトランザクションブロックは互いにロック開放待ちの状態に陥っています。
プログラム1が口座Aのロックを開放しない限りプログラム2が口座Aのロックを取得できず、
プログラム2が口座Bのロックを開放しない限りプログラム1が口座Bのロックを取得できない、
しかし、
プログラム1が口座Bのロックを取得しない限り口座Aのロックを開放できず、
プログラム2が口座Aのロックを取得しない限り口座Bのロックを開放できない、
という、放置しておくと永久にロックを取得できない状態に陥ります。
この状態のことを デッドロック といいます。
デッドロック
ちなみに、
「ロック」のスペルは "Lock"” (=鍵) です。
「暗礁に乗り上げた」の「礁」は "Rock" (=岩) です。
たまに「デッドロックに乗り上げた」などと言う人が居ますが、間違いなので気をつけるように。
参考: 「デッドロックに乗り上げる」という言い方は? (NHK放送文化研究所)
PostgreSQLでは、行ロックの取得待ちが一定時間以上続くと、
アルゴリズムでデッドロックを検出して強制的にトランザクションブロックを終了させてくれます。
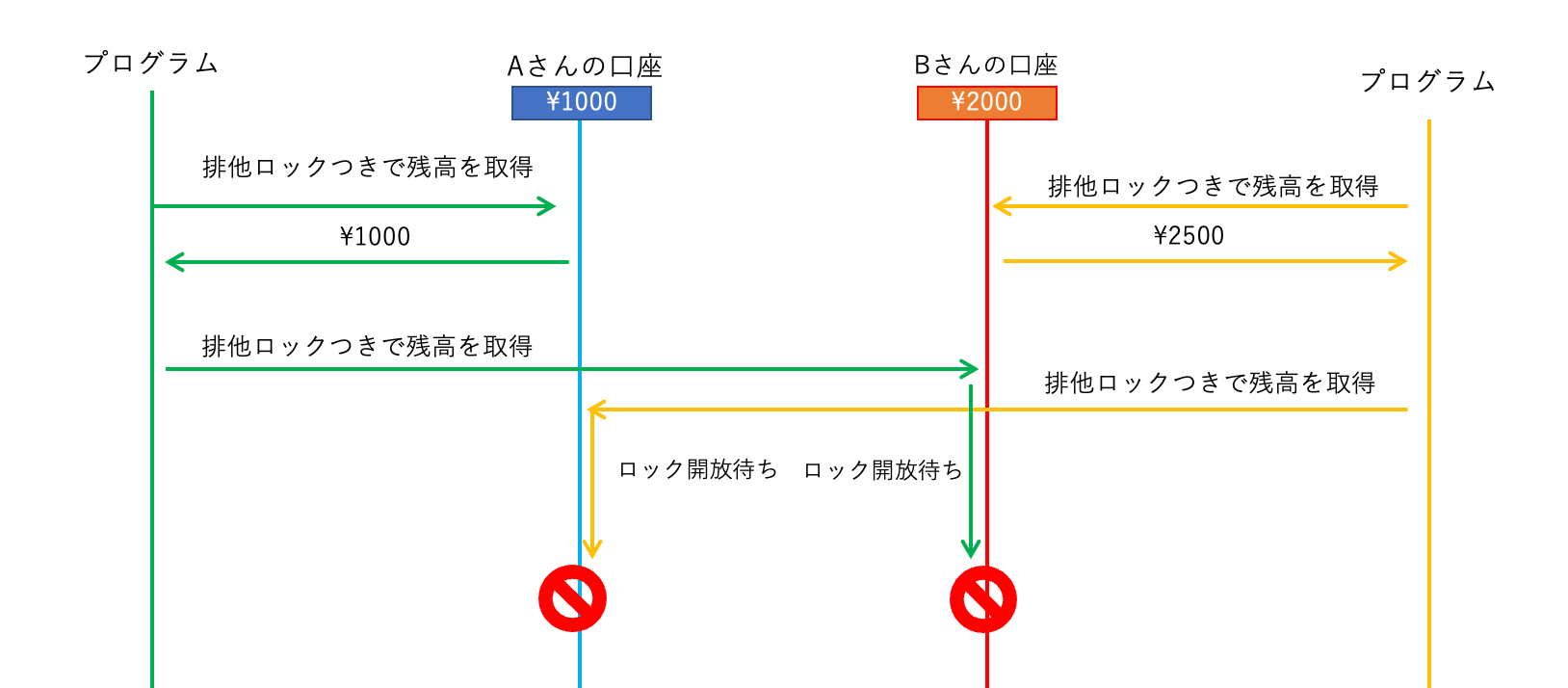
解決策はいくつかあります。
このトランザクションブロックの場合、
「A の残高と B の残高のどちらを先に取得するか」が処理に影響を与えることはありません。
なので「name カラムを昇順でソートして上にあるほうから」SELECT を実行する、
ということによってデッドロックを避けることができます。
SELECT 文を1つにまとめればいいのでは? と思われるかもしれませんが、
このときも IN 句の中身をソートしておく必要があります。
↓左のウィンドウで実行 = プログラム1 (AからBへ500円振り込む) ↓右のウィンドウで実行 = プログラム2 (BからAへ1200円振り込む) BEGIN; BEGIN; -- A, Bの残高を調べる SELECT balance FROM accounts WHERE name IN ('A', 'B') FOR UPDATE; -- A, Bの残高を調べる (=ここで待たされる) SELECT balance FROM accounts WHERE name IN ('A', 'B') FOR UPDATE; -- Aの残高から500円減らす UPDATE accounts SET balance = XXXX WHERE name = 'A'; -- Bの残高を500円増やす UPDATE accounts SET balance = XXXX WHERE name = 'B'; COMMIT; -- Bの残高を1200円減らす UPDATE accounts SET balance = XXXX WHERE name = 'B'; -- Aの残高から1200円増やす UPDATE accounts SET balance = XXXX WHERE name = 'A'; COMMIT;
このように、ロックの取得順序が一貫していればデッドロックは発生しません。
ただしデッドロックを絶対に発生させないように予見してプログラムを書くのはとても難しいです。
テーブルが1個や2個の場合だったり、開発者が1人とかであればどうにかなるんですが、
トランザクションの種類やテーブル数が多くなるとかなり無理が出てきます。
したがって「デッドロックは通常、起こりうるもの」という前提のもとで
プログラムを作成することが普通です。
つまり、デッドロックが発生しても複数回リトライすることでリカバーするのです。
Rails の場合、たとえばこんなふうに実装します。(※サンプルコードなので、このままでは動作しません)
retries = 0 begin ActiveRecord::Base.transaction do : : : end logger.info("トランザクションを完了しました。") rescue ActiveRecord::Deadlocked => e if retries < 10 logger.error("デッドロックを検出しました。トランザクションをリトライします") retries += 1 sleep(0.1 * retries) retry else logger.error("デッドロックを検出し、トランザクションのリトライを give up しました") raise end end
さきほど書いた通り1行だけの文でも立派なトランザクションブロックです。なので、極端な場合は1行の INSERT 文だけでもデッドロックを起こすことがあります。
(参考: INSERT 1文だけでもデッドロックするという話 - ngyukiの日記)
Rails で行ロックを使うには、 lock メソッドを使うことです。
これで SELECT 文に FOR UPDATE 節が付与され、行ロックの対象となります。
ActiveRecord::Base.transaction do a = Account.lock.find_by(name: 'A') b = Account.lock.find_by(name: 'B') b.balance = b.balance - 1200 a.balance = a.balance + 1200 a.save b.save end
あるいは、 with_lock メソッドを利用します。
a = Account.find_by(name: 'A') a.with_lock do b = Account.find_by(name: 'B') b.with_lock do b.balance = b.balance - 1200 a.balance = a.balance + 1200 a.save b.save end end
with_lock メソッドを利用すると、ブロック全体が BEGIN 〜 COMMIT で囲まれます。
アドバイザリロック (Advisory Lock)
別名勧告ロックともいいます。
行ともテーブルとも関係しない、任意の数字をキーとしてロックをかけるロックです。
この例では口座番号1, 2をソートしたものをキーとします。
↓左のウィンドウで実行 = プログラム1 (AからBへ500円振り込む) ↓右のウィンドウで実行 = プログラム2 (BからAへ1200円振り込む) BEGIN; -- key=1の排他的勧告ロックを取得する SELECT pg_advisory_lock(1); -- key=2の排他的勧告ロックを取得する SELECT pg_advisory_lock(2); BEGIN; -- key=1の排他的勧告ロックを取得する = 待たされる SELECT pg_advisory_lock(1); -- Aの残高を調べる SELECT balance FROM accounts WHERE name IN ('A'); -- Bの残高を調べる SELECT balance FROM accounts WHERE name IN ('B'); -- Aの残高から500円減らす UPDATE accounts SET balance = XXXX WHERE name = 'A'; -- Bの残高を500円増やす UPDATE accounts SET balance = XXXX WHERE name = 'B'; COMMIT; -- 排他的ロックを解除する SELECT pg_advisory_unlock_all(); -- ロックが解除されたので、続きを実行できるようになるゐ -- key=2の排他的勧告ロックを取得する SELECT pg_advisory_lock(2); -- Bの残高を調べる SELECT balance FROM accounts WHERE name IN ('B'); -- Aの残高を調べる SELECT balance FROM accounts WHERE name IN ('A'); -- Bの残高を1200円減らす UPDATE accounts SET balance = XXXX WHERE name = 'B'; -- Aの残高から1200円増やす UPDATE accounts SET balance = XXXX WHERE name = 'A'; COMMIT; -- 排他的ロックを解除する SELECT pg_advisory_unlock_all();
さて、プログラム1, 2が動いている真っ最中に
「プログラム3」が実行されたとします。
「プログラム3」は、アドバイザリロックの存在を知らない開発者によって開発されました。
それは、ATM から B の口座に3000円入金する、という処理をするプログラムです。
▼プログラム3:
BEGIN; -- Bの残高を調べる SELECT balance FROM accounts WHERE name IN ('B') FOR UPDATE; -- Bの残高を1200円減らす UPDATE accounts SET balance = XXXX WHERE name = 'B'; COMMIT;
このときロストアップデートが発生します。
なぜならプログラム3のトランザクションブロックでは pg_advisory_lock() を使ったロックが実装されていないからです。知らないから仕方ないわけです。
しかしプログラム3を書いた人が悪かったかというと、そういう話でもないですよね。
集団で開発してシチュエーションを想像してください。
複数人で開発をしていると、ロックの適用漏れなど多発するに決まっていますよ。
コードを見ただけでは、こんな罠があるなんて気づくはずもあれません。
そもそも勧告的ロックを知らない人がコードを読んでもわかりっこありません。仮にコメントに書いてあったとしても、そのコメントをちゃんと読んでくれるかどうかは運次第でしょう。
ドキュメントを書いておいたとしても安心はできません。
「とにかくここは危険だから、変更するときにはものすごく注意しろ」というノウハウを 共有し、伝承する必要があります。しかしそれが簡単ではないということは人類の歴史が証明しています。
なので、アドバイザリロックは使わないにこしたことはありません。
使うときには他に解決策がないか、誰かに相談しましょう。
なお、アドバイザリロックは SQL 標準には含まれていないため、RDBMS によって仕様がまったく異なります。Rails で使うには、テーブルロックと同様に生の SQL 文を実行する必要があります。
ActiveRecord::Base.transaction do ApplicationRecord.connection.execute("SELECT pg_advisory_lock(10)") # : ensure ApplicationRecord.connection.execute("SELECT pg_advisory_unlock_all()") end
DBMS を深く理解しないとアプリケーションが作れない理由
ここまでトランザクション (の一部) を学んできました。
いかがでしたか?
これを基礎として、アプリケーションやシステム全体も ACID を満たすように作り込んでいくのが、ソフトウェアエンジニアの仕事です。
ここ、とても大事です。
よく理解しておいてください。
DBMS が ACID を満たしているからといって、アプリケーションやシステム全体が ACID である、というわけではないのです。あくまでプログラマが責任を持って、システム全体が ACID を満たすようにする必要があるのです。大事ですよ。
ここまでで、DBMS を深く理解しないとアプリケーションを作ることなどできない、ということがわかったのではないでしょうか。
ソフトウェアの中心はコードでなく、データです。
最初の UNIX の開発に携わった伝説のプログラマ、Rob Pike が書いた「Cプログラミングの覚え書き」より引用します。
Rule 5. Data dominates. If you've chosen the right data structures and organized things well, the algorithms will almost always be self-evident. Data structures, not algorithms, are central to programming.
原則5: データはすべてを支配する。 正しいデータ構造を選んでものごとをうまく構成すれば、アルゴリズムはほぼ自明になるというものだ。 アルゴリズムではなく、データ構造こそが、プログラミングの中心なのだ。
Rob Pike: Notes on Programming in C (February 21, 1989)
私がコーディングのことをここまで一切話さず、ひたすらデータベースについて話しているのは
それがプログラミングのド真ん中だから、なのです。
Rails の場合は?
Rails でアプリケーションを開発している人のなかには、「ActiveRecord が DB に関するすべてのものごとを吸収してくれている」と思っている方も多いかもしれません。が、それは幻想です。
ActiveRecord が生成した SQL 文をチェックするよう、必ず意識してください。
場合によっては ActiveRecord を使わず、生の SQL 文を書くことも考えるようにしてください。
そうしないと作れないものも世の中にはいっぱいあります。
どうやってテストするの?
…同時にリクエストが発生し、かつタイミングが整ったときにだけ問題が起きる…
それが、トランザクションにまつわるバグの厄介なところです。
意図的に発生させようとすると、リクエストを同時にたくさん送りつけるテストをする必要があります。
しかし、QAテスト時に通常そんなテストは実施しない現場がほとんどでしょう。
実施のコストが非常に高いのと、発見される可能性が非常に低いためです。
何回テストしても問題なくて、
負荷テストしても問題なくて、
本番でも数年間にわたって問題なく動作していたにもかかわらず、
ある日突然たくさん発生するようになった。
……というのは、よくある話です。
有名な「ソフトウェアテストの7原則」で言われている、
原則1 | テストは欠陥があることは示せるが、欠陥がないことは示せない に該当する典型的なケースのひとつですね。
トランザクションの同時実行による不具合を回避するためには、ヒューリスティック (=経験則)とレビューが重要となります。それにはトランザクションのことをよく知っておかなければなりません。
だからトランザクションを理解しておかないとシステムは作れない、と私は言っているのです。
さて、ACID について冒頭で話しましたが、RDBMS を使えば自動的に ACID となるわけではありません。RDBMS においては ACID が完全にサポートされているわけではありません 。
システム全体として ACID とするには、足りない部分を工夫するか、仕様で問題を回避する必要があります。場合によっては機能を断念するなり工夫するなりする必要があります。
とくに分離性と永続性がややこしいので、次回はそこから見ていきます。
おたのしみに!
Techouseでは、社会課題の解決に一緒に取り組むエンジニアを募集しております。 ご応募お待ちしております。